
How web scraping is revealing lobbying and corruption in Peru
Update: With the release of the Panama Papers, a reliable means of exposing corruption and the methods of money laundering and tax evasion are now even more important. Web scraping provides an avenue to find, collate, and organize data without relying on information leaks.
Paid political influence and corruption continue to be major issues in a surprising number of countries throughout the world. The recent "Operation Lava Jato" in Brazil, in which officials from the state company Petrobras were accused of taking bribes from construction companies in exchange for contracts financed with taxpayer money, is a reminder of this. It has been suggested that unregulated lobbying can lead to this kind of corruption and Transparency International, a non-governmental organization that monitors corruption, has strongly recommended that governments regulate lobbying.
I live in Peru and with corruption scandals regularly making headlines, I was curious to see how Peruvian officials fared and to examine the role that lobbyists play in my government.
Is it possible to track lobbying in Peru?
The Peruvian Law of Transparency requires government institutions to maintain a website where they publish the list of people that visit their offices. Every visitor must register their ID document number, the reason they’re visiting, and the public servant whom they are visiting along with the time of entrance, time of exit and date of visit. You can find all of this information on websites such as this.
The problem with open data
While almost all institutions have their visitor list available online, they all suffer from the same model of a broken user interface. One of the major issues with these websites is that you’re not able to search for visitors, you can only browse who visited on a particular day. If you’re looking for a known lobbyist, you would need to visually scan several pages as there can be up to 400 visitors per day in some institutions.
Obviously this method of search is time-consuming, tedious, boring, and it’s easy to miss the person that you are searching for. This problem is compounded when you want to search for a particular person visiting more than one public institution.
The web scraping solution
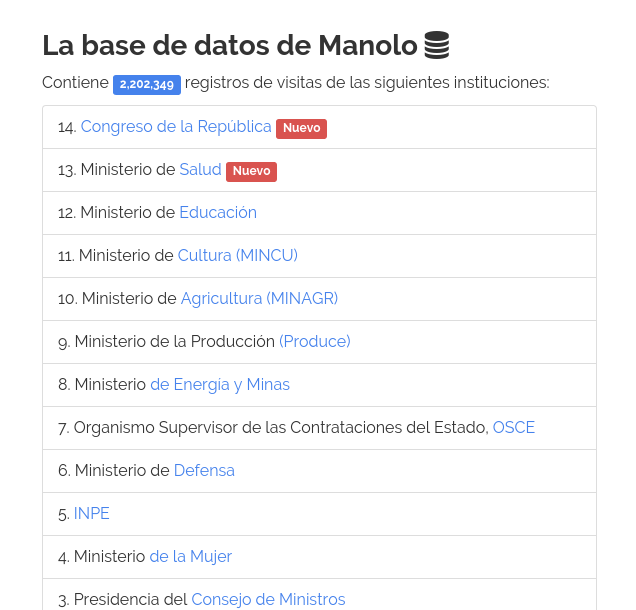
To help journalists track lobbyists, I started the project Manolo. Manolo is a simple search tool that contains the visitor records of several government institutions in Peru. You can type any name and search for any individual across 14 public institutions in a matter of milliseconds.
Under the hood
Unfortunately Peruvian institutions do not provide their visitor data in a structured way. There’s no API to fetch this data in a machine readable format, so the only way to get the information is by scraping their websites and then mining the data.
Manolo consists of a bunch of web scrapers written with Zyte’s popular Python framework Scrapy. The Scrapy spiders crawl the visitor lists once a week, extracting structured data from the HTML content and storing it in a PostgreSQL database. Elasticsearch indexes this data and users can then perform searches via a Django-based web UI, available on the Manolo website.
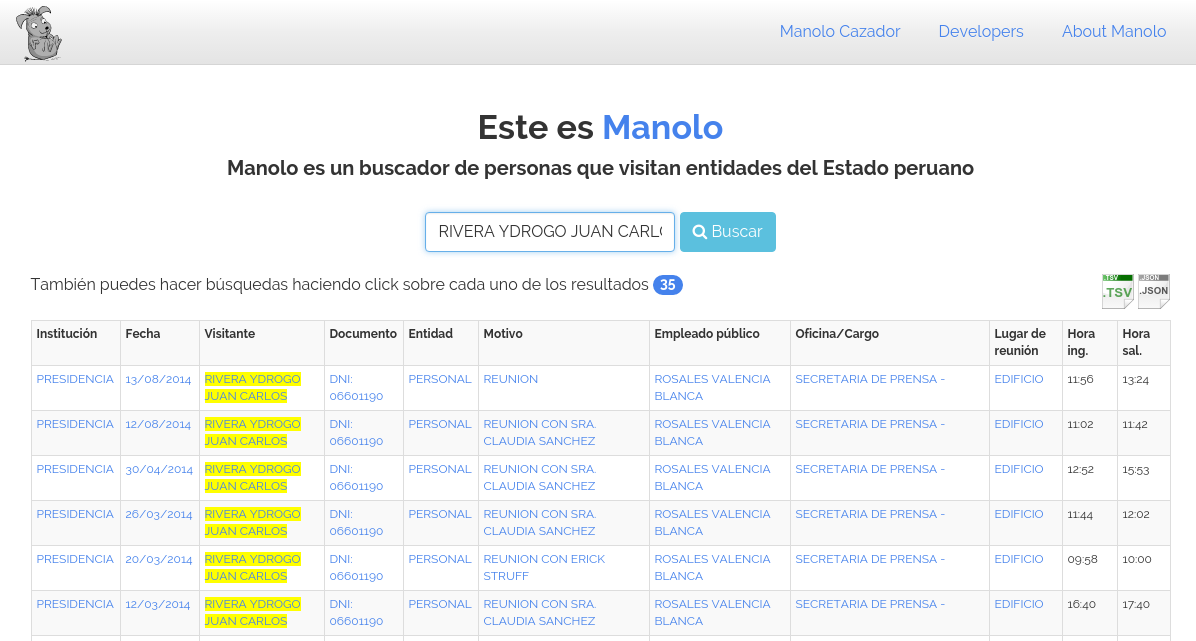
So far, my friend @matiskay and I have created 14 spiders which have scraped more than 2 million records. You can find the source code for the spiders and the search tool here.
Who uses Manolo?
I have always aimed to provide this search tool online for anyone to use free of charge. At the beginning, I was just hoping that I could convince one or two journalists to use Manolo when searching for information.
You can imagine my suprise when two national newspapers (El Comercio and Diario Exitosa), one TV station (Latina) and two news web portals (Utero.pe and LaMula) became active users of Manolo.
One of the most impressive uses of Manolo was when a journalist used it to find out that the legal representative of a company that signed numerous and extremely profitable construction contracts with the government was a regular visitor to the President's residence building. According to the data scraped by Manolo, this representative visited some of the closest allies of the president 33 times. He was already under investigation because his company pocketed the money from the contracts and never built anything.
The discovery of the 33 visits made big headlines in 4 nationwide newspapers. Soon after, journalists from a variety of media outlets started using Manolo to find suspicious visits of known lobbyists to ministries responsible for the construction of public infrastructure. They even found that lobbyists involved in the famous "Lava Jato" corruption scandal were also regular visitors of Peruvian institutions.

"Chocherin Visited Government Palace 33 Times"
Wrap Up
Government corruption through lobbying is shockingly prevalent. Transparency is the solution, but even publicly available information can be convoluted and difficult to access. And that’s where web scraping comes in. Open data is what we should all be striving towards and hopefully others will follow Manolo’s lead.
Our use of Scrapy can easily be applied to any other situation where you are looking to scrape websites for information on government officials (or anyone else, for that matter).