
Web data analysis: Exposing NFL player salaries with Python
Football. From throwing a pigskin with your dad, to crunching numbers to determine the probability of your favorite team winning the Super Bowl, it is a sport that's easy to grasp yet teeming with complexity. From game to game, the amount of complex data associated with every team - and every player - increases, creating a more descriptive, timely image of the League at hand.
By using web scraping and data analytics, the insights that we, the fans, crave - especially during the off-season - become accessible. Changing agreements, draft picks, and all the juicy decisions made in the off-season generate a great deal of their own data.
By using a few simple applications and tricks we can see the broader patterns and landscapes of the sport as a whole. Salary data is especially easy to scrape, and for the purposes of this article, we’ll build a scraper to extract this data from the web, then teach you how to use simple data analytics to answer any questions we might have.
Amid this sea of data, interesting insights appear, like the correlation between age and salary, who gets the biggest and smallest paycheck, or which position brings in the most cash. To get the information we need to make these conclusions, we’re going to extract NFL players’ salary data from a public source. Then, using that data, we’ll create ad-hoc reports to unearth patterns hidden in the numbers.
In this article, guest writer Attila Tóth, founder of ScrapingAuthority.com, will give you a bird’s eye view of how to scrape, clean, store, and analyze unstructured public data. In addition to the code, we’ll demonstrate our thought process as we go through each step. Whether you want to build a scrapy spider or only work on data analysis, there’s something here for everybody.
The site we’re going to scrape is overthecap.com, a site that has all kinds of information about NFL player contracts and salaries.
Tools
For this project we will use the Scrapy web scraping framework for data extraction; a MySQL database to store said data; a pandas library to work with data, and the tried-and-true matplotlib for charting.
Prerequisites
- Python 2 or 3
- Scrapy and its dependencies
- Python MySQL connector (We’re using pymysql in this case)
- pandas
- matplotlib
Process
We will use the following process to complete the project:
- Data extraction
- Data cleaning and processing
- Building pipelines
- Data analyzing
- Conclusions
Data extraction
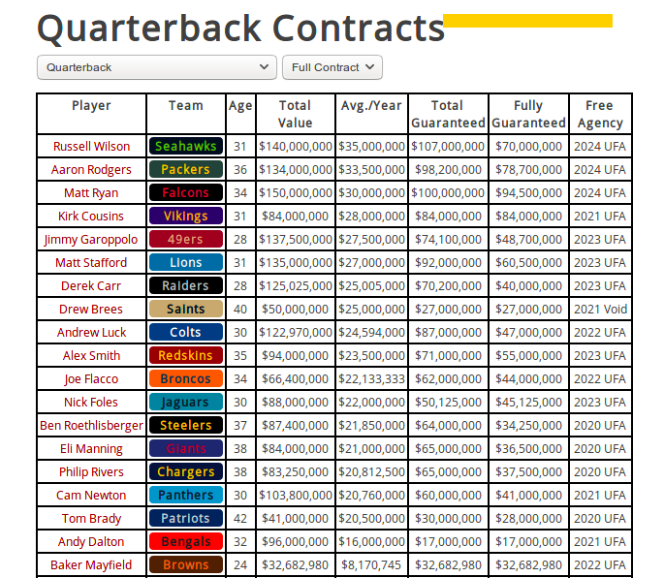
Here is an example URL of the quarterback page we want to extract data from:
https://overthecap.com/position/quarterback/
However, we will be extracting data for all positions.
Our spiders will be designed to extract data from the following fields: player, team, age, position, total_value, avg_year, total_guaranteed, fully_guaranteed, free_agency_year.
Inspecting the website
As always, we first need to inspect the website to be able to extract the target data.
Let’s kick-off by starting a new Scrapy project:
scrapy startproject NFLSalaries
Item
In order to fetch the data with Scrapy, we need an item defined in the items.py file. We will call it ContractItem:
class ContractItem(Item):
player = Field()
team = Field()
position = Field()
age = Field()
total_value = Field()
avg_year = Field()
input_processor=MapCompose()
total_guaranteed = Field()
fully_guaranteed = Field()
free_agency_year = Field()
Now we’re done with defining the item, let's start coding the spider.
Spider
There are two challenges we need to overcome when designing our spider:
- “Clicking” through each position using the dropdown menu, enabling us to extract data from all player positions, not just quarterbacks.
- Selecting rows, one-by-one, and returning populated items.
There are multiple ways to implement this spider, however, for this project we decided to use an approach that is the most straightforward and simple.
First, create a new spider python file and inside the file a class for our spider:
class ContractSpider(Spider):
Then define name and start_urls:
name = "contract_spider" start_urls = ["https://overthecap.com/position/"]
Now we need to implement the parse function. Inside this function, we usually populate the item. However, in this case, we first need to make sure that we’re grabbing data from all the position pages (quarterback, running-back, etc.).
In the parse function we are doing exactly that: finding the URLs and requesting each of them so we can parse them later:
def parse(self, response):
for position_slug in response.css("#select-position > option::attr(value)").extract():
url = self.start_urls[0] + position_slug
yield Request(url, callback=self.extract, meta={"position": position_slug})
So what does our parse function actually do here?
The parse function iterates over each dropdown element (positions). Then inside the iteration, we extract the URL for the actual page where we want to get data from. Finally, we request this page and pass the position info as metadata for the extract function, which will be coded next.
The extract function will need to deal with actual data extraction and item population. As we previously learned from inspecting the website, we know that each table row contains one item. So we’ll iterate over each row to populate each item. Easy right?
But remember that we want the data to be written into a database at the end. To simplify that, we’re using item loaders and i/o processors to clean the extracted data.
def extract(self, response):
for row in response.css(".position-table > tbody > tr"):
item_loader = ItemLoader(item=ContractItem(), selector=row)
# removes html tags
item_loader.default_input_processor = MapCompose(remove_tags)
# takes only the first element
item_loader.default_output_processor = TakeFirst()
# selecting fields separately
item_loader.add_css("player", "td:nth-of-type(1)")
item_loader.add_css("team", "td:nth-of-type(2)")
item_loader.add_css("age", "td:nth-of-type(3)")
item_loader.add_css("total_value", "td:nth-of-type(4)")
item_loader.add_css("avg_year", "td:nth-of-type(5)")
item_loader.add_css("total_guaranteed", "td:nth-of-type(6)")
item_loader.add_css("fully_guaranteed", "td:nth-of-type(7)")
item_loader.add_css("free_agency_year", "td:nth-of-type(8)")
item_loader.add_value("position", response.meta["position"])
# yielding a populated item yield item_loader.load_item()
The next step is to implement the input processors which will clean our freshly extracted data.
Cleaning and processing
Let’s make use of item loader input and output processors. There are two main tasks that the processors need to accomplish: removing HTML tags and converting data. Removing HTML tags is important because we don’t want messy data in our database.
The conversion part is important because our database table, which we will write into, will have number and text columns as well. And so we need to make sure that we are inserting actual numbers as number fields and cleaned text data as text fields.
The fields that need processing (other than removing HTML tags) include age, total_value, avg_year, total_guaranteed, fully_guaranteed, free_agency_year.
As all of these fields are number fields they need further processing:
# converting salary to int
def clean_amount(value):
return int(value.replace(",", "").replace("$", ""))
# converting text to int
def to_number(value):
if value != "":
return int(value)
return None
age = Field(
input_processor=MapCompose(remove_tags, to_number)
)
total_value = Field(
input_processor=MapCompose(remove_tags, clean_amount)
)
avg_year = Field(
input_processor=MapCompose(remove_tags, clean_amount)
)
total_guaranteed = Field(
input_processor=MapCompose(remove_tags, clean_amount)
)
fully_guaranteed = Field(
input_processor=MapCompose(remove_tags, clean_amount)
)
free_agency_year = Field(
input_processor=MapCompose(remove_tags, lambda value: value.split(" ")[0], to_number)
)
Pipelines
At this point, our extracted data is clean and ready to be stored inside a database. But before that, we need to remember that we likely have plenty of duplicates because some players hold multiple positions. For example, a player can be a safety and a defensive-back at the same time. So this player would be in the database multiple times. We don’t want redundant data corrupting our data set, so we need to find a way to filter duplicates whilst scraping.
Duplicate filtering
The solution for this is to write an item pipeline that drops the actual item if the player has already been scraped. Add this pipeline to our pipelines.py file:
class DuplicatesPipeline(object): def __init__(self): self.players = set()
def process_item(self, item, spider):
if item["player"] in self.players:
raise DropItem("This player has already been stored: %s" % item)
else: self.players.add(item["player"])
return item
This pipeline works by continuously saving scraped player names in self.players, which is a set. If the player has already been processed by the spider it raises a warning message and simply drops (ignores) the item. If the currently processed player has not been processed yet then no need to drop the item.
Database pipeline
One of the best ways to write a database pipeline in Scrapy is as follows:
- Add db connection settings in settings.py
DB_SETTINGS = {
"db": "nfl_contracts",
"user": "root",
"passwd": "root",
"host": "localhost"
}
2. Create a new pipeline class and a constructor to initiate db connection.
class DatabasePipeline(object):
def __init__(self, db, user, passwd, host):
self.conn = pymysql.connect(
host=host,
user=user,
passwd=passwd,
db=db)
self.cursor = self.conn.cursor()
3. Override from_crawler function to get db settings.
@classmethod
def from_crawler(cls, crawler):
db_settings = crawler.settings.getdict("DB_SETTINGS")
if not db_settings:
raise NotConfigured
db = db_settings["db"]
user = db_settings["user"]
passwd = db_settings["passwd"]
host = db_settings["host"]
return cls(db, user, passwd, host)
4. Insert item into the database
def process_item(self, item, spider):
query = ("INSERT INTO Contract (player, team, position, age, total_value, avg_year, "
"total_guaranteed, fully_guaranteed, free_agency_year, free_agency_type)"
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)")
self.cursor.execute(query, (item["player"],
item["team"],
item["position"],
item["age"],
item["total_value"],
item["avg_year"],
item["total_guaranteed"],
item["fully_guaranteed"],
item["free_agency_year"],
item["free_agency_type"]
)
)
self.conn.commit()
return item
5. Close db connection when the spider finishes
def close_spider(self):
self.conn.close()
Analyzing
We’ve extracted data. Cleaned it. And saved it into a database. Finally, here comes the fun part: trying to get some actual insights into NFL salaries.
Let’s see if we find something interesting. For each report, we’re going to use pandas dataframes to hold the queried data together.
Descriptive reports
Now, let’s create some ad hoc reports using the database we’ve generated to answer some simple questions, like “Who is the youngest player?” and “When will the longest active contract end?”
To do so, let’s fetch all the data into a dataframe. We will need to create a new dictionary based on the dataframe to get min, max, mean and median values for all the data fields. Then create a new dataframe from the dict to be able to display it as a table.
query = ("SELECT age, avg_year AS yearly_salary, free_agency_year,
fully_guaranteed, total_guaranteed, total_value FROM Contract")
df = pd.read_sql(query, self.conn)
d = {“Mean”: df.mean(),
“Min”: df.min(),
“Max”: df.max(),
“Median”: df.median()}
pd.DataFrame.from_dict(d, dtype='int32')[["Min", "Max", "Mean",
"Median"]].transpose()
This table contains some basic descriptive information about our data.
- The youngest NFL player is 21 years old. He is Tremaine Edmunds, linebacker for the Buffalo Bills will be 21 in May, and was drafted in 2018 with the 16th pick.
- The oldest player is Adam Vinatieri, 47. He’s going to start his 24th season as a kicker in the NFL.
- The average age is 26.
- The longest currently active contract will end in 2025.
- Among currently active contracts, the median contract length is two years.
Minimum and maximum salaries
Here let's query the data set to identify which players have the highest and lowest salaries:
query = ("SELECT player, age, position, team, avg_year AS yearly_salary,
free_agency_year FROM Contract "
"ORDER BY avg_year ASC LIMIT 5")
return pd.read_sql(query, self.conn)
The minimum yearly salary for an NFL player is $480,000 (in the 2019 season it’s going to be $15,000 more). Tanner Lee, 24, QB for the Jags, is the only player who got this amount of money, in his rookie season. For some unknown reason, other teams stick to $487,500 when it comes to the minimum payment.
query = ("SELECT player, age, position, team, avg_year AS yearly_salary,
free_agency_year FROM Contract "
"ORDER BY avg_year DESC LIMIT 5")
return pd.read_sql(query, self.conn)
The top five players with the biggest paycheck are all QBs, which is not surprising. Aaron Rodgers is the 1st with a yearly average salary of $33,500,000. The youngest in the top five is Jimmy Garoppolo, 28, with a solid $28,000,000 average yearly salary. Except for Kirk Cousins, they all have long-term contracts (4+ years remaining).
Long-term contracts
Next, let's see which players have the longest contracts until they become a free-agent:
query = ("SELECT player, age, position, team, avg_year, free_agency_year
FROM Contract "
"ORDER BY free_agency_year DESC LIMIT 4")
return pd.read_sql(query, self.conn)
Contract length distribution across players
Next, let's look at the contract length distribution across players to see what is the average active contract length:
query = ("SELECT (free_agency_year-2019) AS contract_length FROM Contract")
df = pd.read_sql(query, self.conn)
df[["contract_length"]].plot(kind="hist", bins=range(0, 8), color="orange")
plt.ylabel("Number of players")
plt.xlabel("Remaining years of the contract")
plt.show()
Correlation between contract length and player’s age
To dig a little deeper we then looked at the correlation between a players age and their contract length:
query = ("SELECT age, AVG(free_agency_year-2019) AS contract_length "
"FROM Contract WHERE age IS NOT NULL "
"GROUP BY age ORDER BY age ASC")
df = pd.read_sql(query, self.conn)
df.plot(kind="line", x="age", y="contract_length", color="red")
plt.show()
This graph shows the correlation between a player’s age and the remaining years of his contract (contract length). There’s a downhill trend between age 22 and 26, which probably suggests that most of the players of this age still have their rookie contracts. At age 26 they start negotiating new contracts hence the uphill climb. The average rookie contract is a 3-year deal but after that, an average player receives a 1 or 2-year contract.
Age distribution
query = ("SELECT age FROM Contract WHERE age IS NOT NULL")
df = pd.read_sql(query, self.conn)
df[["age"]].plot(kind="hist", bins=range(20, 50), xticks=range(20, 50, 2), color="teal")
plt.ylabel("Number of players")
plt.xlabel("Age")
plt.show()
Age distribution by position
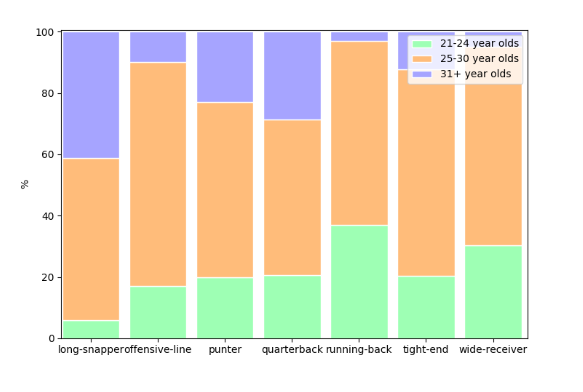
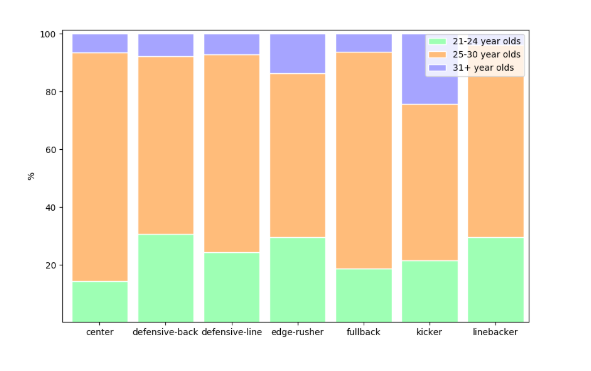
Some quick remarks:
- 40% of long snappers are 31+ years old. Almost no 21-24 years old here.
- The second in the list is the QB position, around 30% of QBs are 31+ years old.
- The center position has the highest ratio of 25-30-year-olds.
- RBs have the highest ratio of 21-24-year-olds. almost 40%.
Longer contract means larger salary per year?
query = ("SELECT (free_agency_year-2019) AS years_left, FLOOR(AVG(avg_year)) AS avg_yearly_salary "
"FROM Contract GROUP BY years_left")
df = pd.read_sql(query, self.conn)
ax = plt.gca()
ax.get_yaxis().get_major_formatter().set_useOffset(False)
ax.get_yaxis().get_major_formatter().set_scientific(False)
df.plot(kind="line", x="years_left", y="avg_yearly_salary", color="red", ax=ax)
plt.show()
Conclusion
We covered website inspection, data extraction, cleaning, processing, pipelines, and descriptive analysis. If you’ve read this far I hope this article has given you some practical tips on how to leverage web scraping. Web scraping is all about giving you the opportunity to gain insights and make data-driven decisions. Hopefully, this tutorial will inspire future projects and exciting new insights.
Your web scraping project
At Zyte we have extensive experience architecting and developing data extraction solutions for every possible use case. If you have a need to start or scale your web scraping project then our Solution architecture team is available for a free consultation, where we will evaluate and architect a data extraction solution to meet your data and compliance requirements.
At Zyte we always love to hear what our readers think of our content and any questions you might have. So please leave a comment below with what you thought of the article and what you are working on.
Thanks for reading!
The full source code of this tutorial is available on Github, click here!
-----------------------------------------------------------------------------------------------------------------------------
Attila Tóth
Founder of ScrapingAuthority.com where he teaches web scraping and data engineering. Expertise in designing and implementing web data extraction and processing solutions.