
Web scraping to create open data
Open data is the idea that some data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control.
My first experience with open data was in the year 2010. I wanted to create a better app for Bicing, the local bike sharing system in Barcelona. Their website was a nightmare to use and I was tired of needing to walk to each station, trying to guess which ones had bicycles. There was no app for Android, other than a couple of unofficial attempts that didn’t work at all.
I began as most would; I searched the internet and found a library named python-bicing that was somehow able to retrieve station and bike information. This was my first time using Python and, after some investigation, I learned what the code was doing: accessing the official website, parsing the JavaScript that generated their buggy map and giving back a nice chunk of Python objects that represented bike share stations.
This I learned was called web scraping. It was like I had figured out a magic trick that would allow me to always be able to access the data I needed without having to rely on faulty websites.
The rise of OpenBicing and CityBikes
Shortly after, I launched OpenBicing, an Android app for the local bike sharing system in Barcelona, together with a backend that used python-bicing. I also shared a public API that provided this information so that nobody else had to do the dirty work ever again.
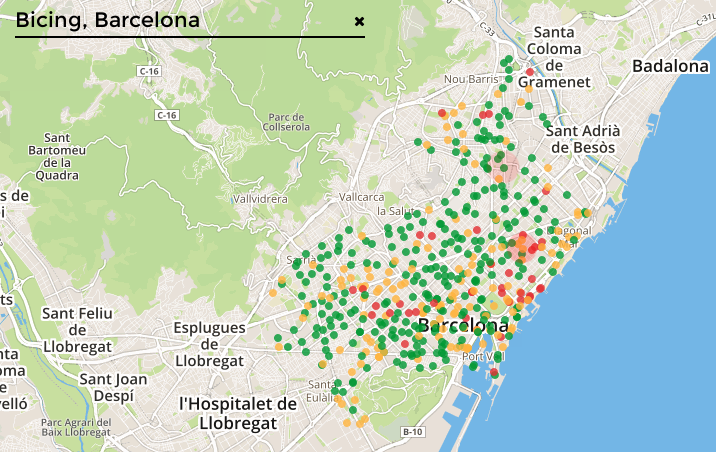
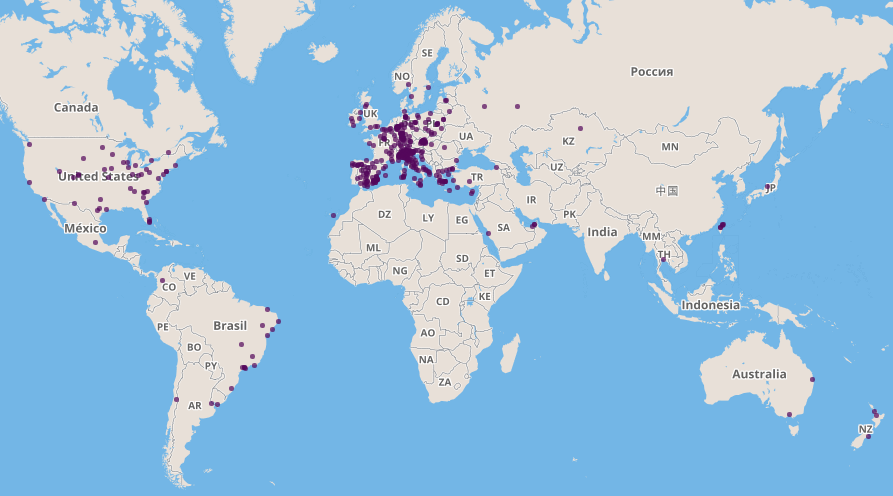
Since other cities were having the same problem, we expanded the scope of the project worldwide and renamed it CityBikes. That was 6 years ago.

To date, CityBikes is the most comprehensive and widely used open API for bike sharing information, with support for over 400 cities worldwide. Our API processes around 10 requests per second and we scrape each of the 418 feeds about every three minutes. Making our core library available for anyone to contribute has been crucial in maintaining and adding coverage for all of the supported systems.
The open data fallacy
We are usually regarded as "an open data project" even though less than 10% of our feeds come from properly licensed, documented and machine-readable feeds. The remaining 90% is composed of 188 feeds that are machine-readable, but not licensed nor documented and 230 that are entirely maintained by scraping HTML pages.
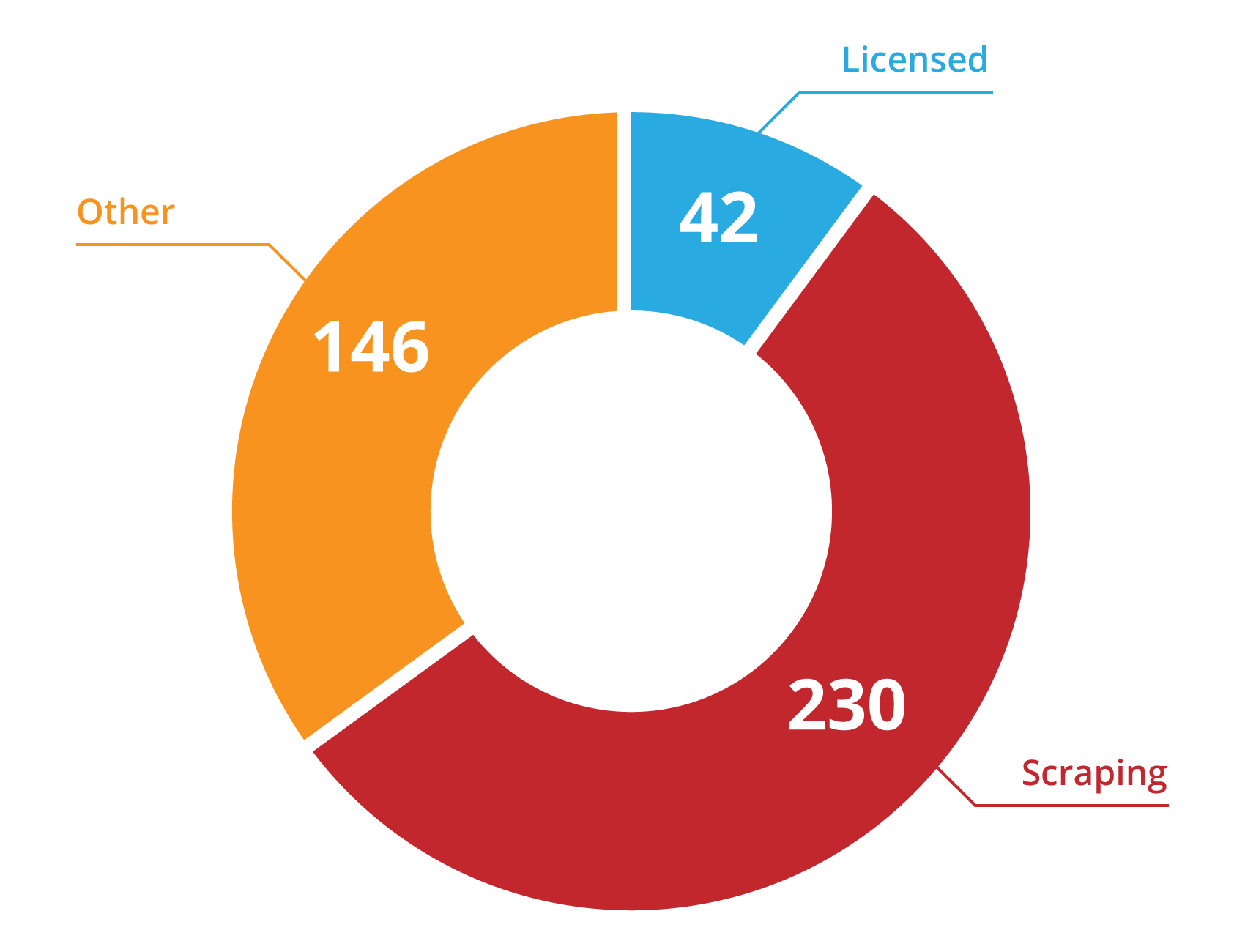
NABSA (North American BikeShare Association) recently published GBFS (General Bikeshare Feed Specification). This is clearly a step in the right direction, but I can’t help but look at the almost 60% of services we currently support through scraping and wonder how long it will take the remaining organizations to release their information, if ever. This is even more the case considering these numbers aren’t even taking into account worldwide coverage.
Over the last few years there has been a progression by transportation companies and city councils toward providing their information as "open data". Directive 2003/98/EC encourages EU member states to release information regarding public services.
Yet, in most cases, there’s little action in enforcing Public Private Partnerships (PPP) to release their public information under a non-restrictive license or even to transfer ownership of the data to city councils to be included in their open data portals.
Even with the increasing number of companies and institutions interested in participating in open data, by no means should we consider open data a reality or something to be taken for granted. I firmly believe in the future and benefits of open data, I have seen them happening all around CityBikes, but as technologists we need to stress the fact that the data is not out there yet.
The benefits of open data
When I started this project, I sought to make a difference in Barcelona. Now you can find tons of bike sharing apps that use our API on all major platforms. It doesn't matter that these are not our own apps. They are solving the same problem we were trying to fix, so their success is our success.
Besides popular apps like Moovit or CityMapper, there are many neat projects out there, some of which are published under free software licenses. Ideally, a city council could create a customization of any of these apps for their own use.
Most official applications for bike sharing systems have terrible ratings. The core business of transportation companies is running a service, so they have no real motivation to create an engaging UI or innovate further. In some cases, the city council does not even own the rights to the data, being completely at the mercy of the company providing the transportation service.
Open data over apps
When providing public services, city councils and companies often get lost in what they should offer as an aid to the service. They focus on a nice map or a flashy application, rather than providing the data behind these service aids. Maps, apps, and websites have a limited focus and usually serve a single purpose. On the other hand, data is malleable and the purest form of representation. While you can’t create something new from looking and playing with a static map (except, of course, if you scrape it), data can be used to create countless different iterations. It can even provide a bridge that will allow anyone to participate, improve and build on top of these public services.
Wrap Up
At this point, you might wonder why I care so much about bike sharing. To me it’s not about bike sharing anymore. CityBikes is just too good of an open data metaphor, a simulation in which public information is freely accessible to everyone. It shows the benefits of open data and the deficiencies that arise from the lack thereof.
We shouldn't have to create open data by scraping websites. This information should be already available, easily accessed and provided in a machine-readable format from the original providers, be they city councils or transportation companies. However, until there's another option, we’ll always have scraping.