
Scrapy + MonkeyLearn: Textual analysis of web data
We recently announced our integration with MonkeyLearn, bringing machine learning to Scrapy Cloud. MonkeyLearn offers numerous text analysis services via its API. Since there are so many uses to this platform addon, we’re launching a series of tutorials to help get you started.

To kick off the MonkeyLearn Addon Tutorial series, let’s start with something we can all identify with: shopping. Whether you need to buy something for yourself, friends or family, or even the office, you need to evaluate cost, quality, and reviews. And when you’re working on a budget of both money and time, it can be helpful to automate the process with web scraping.
When scraping shopping and e-commerce sites, you’re most likely going to want product categories. Typically, you’d do this using the breadcrumbs. However, the challenge comes when you want to scrape several websites at once while keeping categories consistent throughout.
This is where MonkeyLearn comes in. You can use their Retail Classifier to classify products based on their descriptions, taking away the ambiguity of varied product categories.
This post will walk you through how to use MonkeyLearn’s Retail Classifier through the MonkeyLearn addon on Scrapy Cloud to scrape and categorise products from an online retailer.
Say Hello to Scrapy Cloud 2.0
For those new readers, Scrapy Cloud is our cloud-based platform that lets you easily deploy and run Scrapy and Portia web spiders without needing to deal with servers, libraries and dependencies, scheduling, storage, or monitoring. Scrapy Cloud recently underwent an upgrade and now features Docker support and a whole host of other updates.
In this tutorial, we’re using Scrapy to crawl and extract data. Scrapy’s decoupled architecture lets you use ready-made integrations for your spiders. The MonkeyLearn addon implements a Scrapy middleware. The addon takes every item scraped and sends the fields of your choice to MonkeyLearn for analysis. The classifier then stores the resulting category in another field of your choice. This lets you classify items without any extra code.
If you are a new user, sign up for Scrapy Cloud for free to continue on with this addon tutorial.
Meet MonkeyLearn's Retail Classifier
We’ll begin by trying out the MonkeyLearn Retail Classifier with a sample description:
Enjoy speedy Wi-Fi around your home with this NETGEAR Nighthawk X4 AC2350 R7500-100NAS router, which features 4 high-performance antennas and Beamforming+ technology for optimal wireless range. Dynamic QoS prioritization automatically adjusts bandwidth.
Paste this sample in the test form under the Sandbox > Classify tab. And hit Submit:
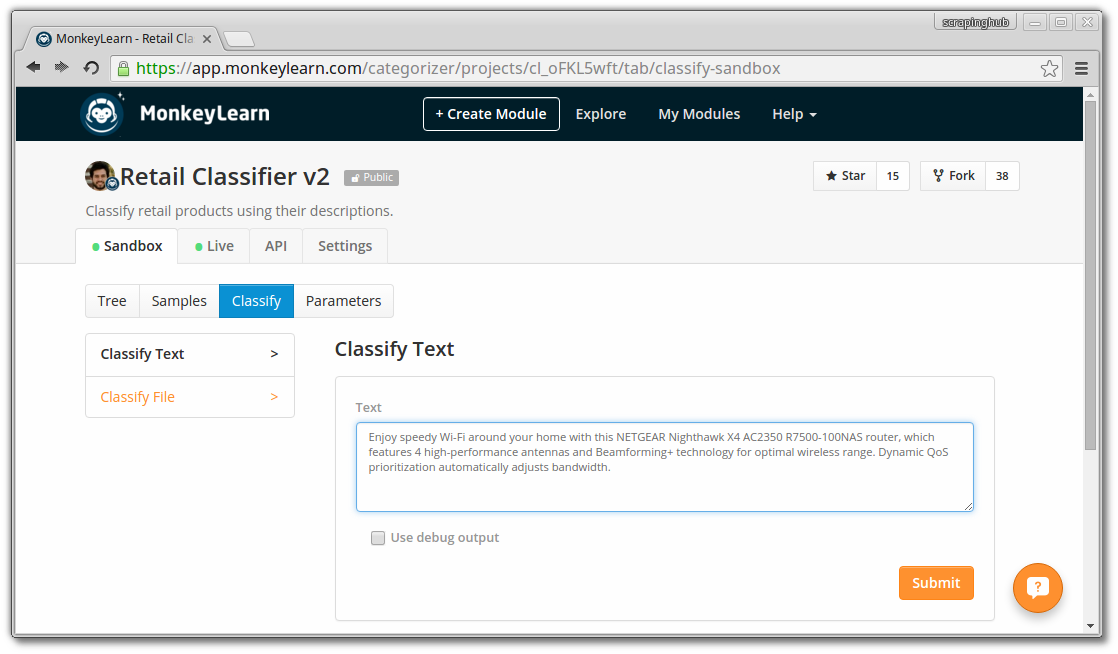
You should get the following results:
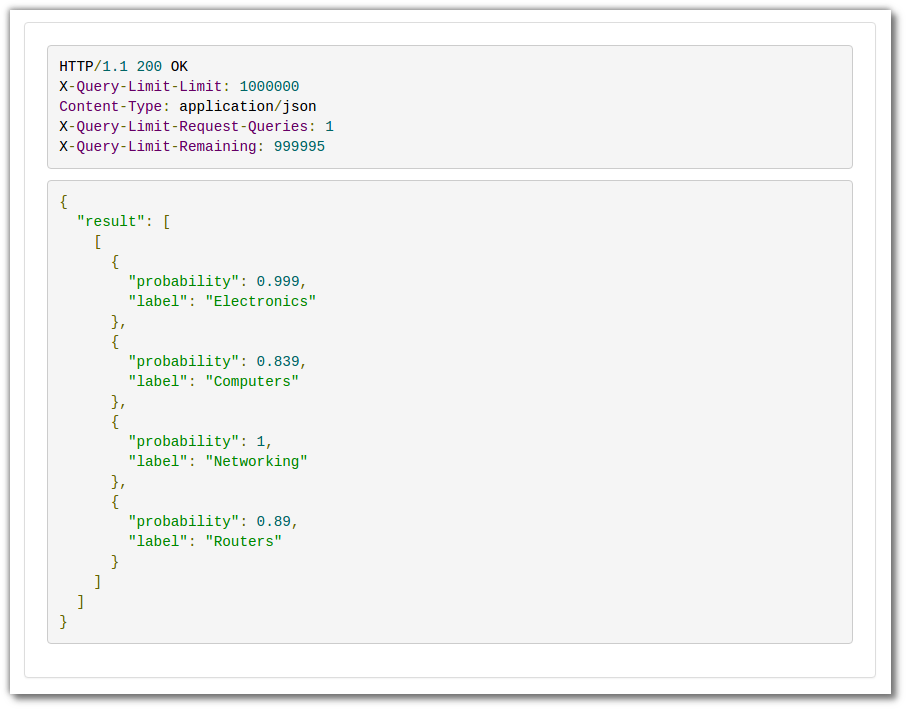
MonkeyLearn's engine analyzed the description and identified that the product belongs in the Electronics / Computers / Networking / Routers categories. As a bonus, it specifies how sure it is of its predictions.
The same example using curl would be:
curl --data '{"text_list": ["Enjoy speedy Wi-Fi around your home with this NETGEAR Nighthawk X4 AC2350 R7500-100NAS router, which features 4 high-performance antennas and Beamforming+ technology for optimal wireless range. Dynamic QoS prioritization automatically adjusts bandwidth."]}' -H "Authorization:Token <YOUR TOKEN GOES HERE>" -H "Content-Type: application/json" -D - "https://api.monkeylearn.com/v2/classifiers/cl_oFKL5wft/classify/?"
You can sign up for free on MonkeyLearn and replace <YOUR TOKEN GOES HERE> with your particular API token to play with the retail classifier further.
Using MonkeyLearn with a Scrapy Cloud Project
Now we are going to deploy a Scrapy project to Scrapy Cloud and use the MonkeyLearn addon to categorize the scraped data. You can clone this project, or build your own spiders, and follow the steps described below.
1. Build your Scrapy spiders
For this tutorial, we built a spider for a fictional e-commerce website. The spider is pretty straightforward so that you can easily clone the whole project and try it by yourself. However, you should be aware of some details when building a spider from scratch to use with the MonkeyLearn addon.
First, the addon requires your spiders to generate Item objects from a pre-defined Item class. In our case, it's the ProductItem class:
class ProductItem(scrapy.Item): url = scrapy.Field() title = scrapy.Field() description = scrapy.Field() category = scrapy.Field() Second, you have to declare where the MonkeyLearn addon will store the analysis' results as an additional field in your Item class. For our spider, these results will be stored in the category field of each of the items scraped.
2. Setup shub
Shub is the command line tool to manage your Scrapy Cloud services and you will use it to deploy your Scrapy projects there. You can install it by:
$ pip install shub
Now authenticate yourself on Scrapy Cloud:
$ shub login Enter your API key from https://app.Zyte.com/account/apikey API key: Validating API key... API key is OK, you are logged in now.
You can get your API key in your account profile page.
3. Deploy your project
First go to Scrapy Cloud's web dashboard and create a project there.
$ cd product-crawler $ shub deploy Target project ID:
Now your project is ready to run in Scrapy Cloud.
4. Enable the MonkeyLearn addon on Scrapy Cloud
Note that before you enable the addon, you have to create an account on MonkeyLearn.
To enable the addon, head to the Addons Setup section in your Scrapy Cloud project's settings:
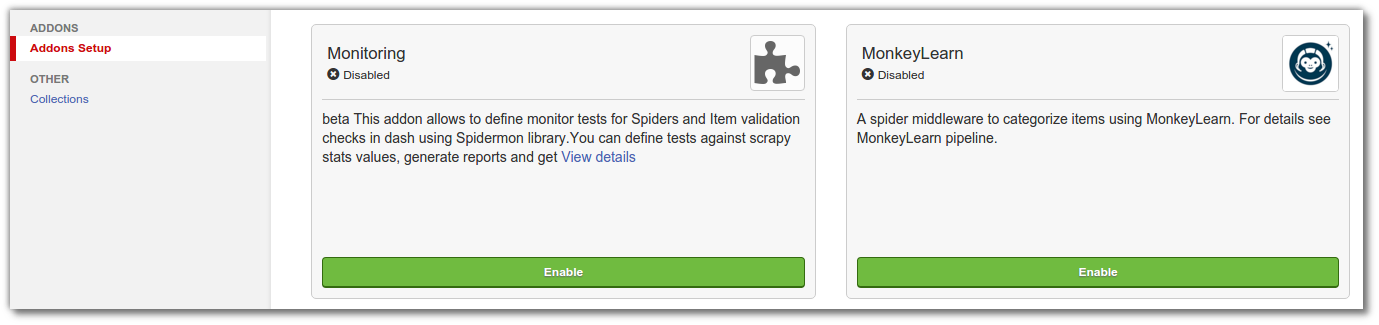
You can configure the addon with the following settings:
- MonkeyLearn token: your MonkeyLearn API token. You can access it from your account settings on the MonkeyLearn website.
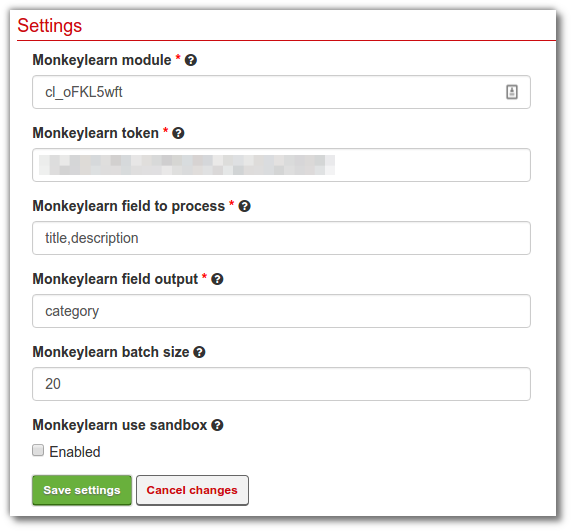
- MonkeyLearn field to process: a list of item text fields (separated by commas) that will be used as input for the classifier. In this tutorial it is: title,description.
- MonkeyLearn field output: the name of the new field that will be added to your items in order to store the categories returned by the classifier.
- MonkeyLearn module: the id of the classifier that you are going to use. In this tutorial, the id is 'cl_oFKL5wft’.
- MonkeyLearn batch size: the amount of items the addon will retain before sending to MonkeyLearn for analysis.
You can find the id of any classifier in the URL:
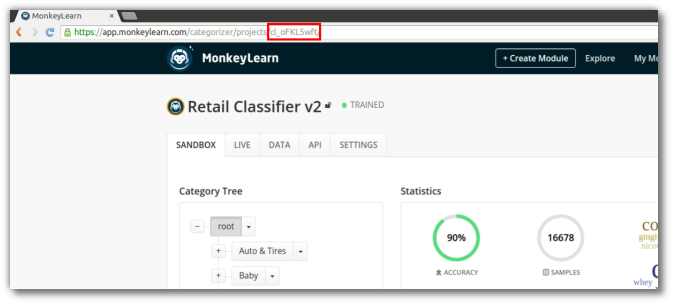
When you’re done filling out all the fields, the addon configuration should look something like this:
5. Run your Spiders
Now that you have the Retail Classifier enabled, run the spider by going to your project’s Jobs page. Click ‘Run Spider’, select the spider and then confirm.
Give the spider a couple of minutes to gather results. You can then view the job's items and you should see that the category field has been filled by MonkeyLearn:
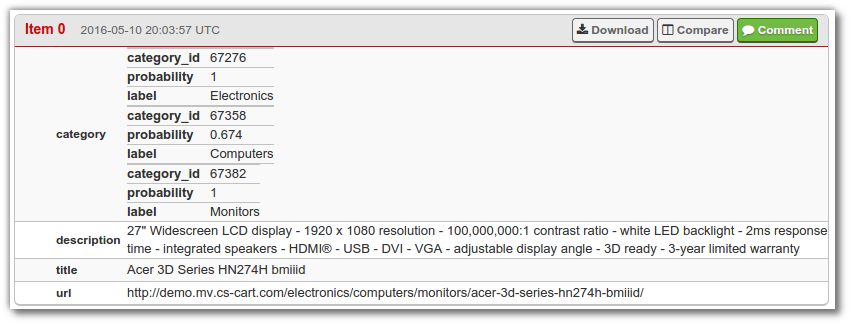
You can then download the results as a JSON or XML file and then categorize the products by the categories and probabilities returned by the addon.
Wrap Up
Using MonkeyLearn’s Retail Classifier with Scrapy on Scrapy Cloud allows you to immediately analyze your data for easier categorization and analysis. So the next time you’ve got a massive list of people to shop for, try using immediate textual analysis with web scraping to simplify the process.
We’ll continue the series with walkthroughs on using the MonkeyLearn addon for language detection, sentiment analysis, keyword extraction, or any custom classification or extraction that you may need personally or professionally. We’ll explore different uses and hopefully help you make the most of this new platform integration.
If you haven’t already, sign up for MonkeyLearn (for free) and sign up for the newly upgraded Scrapy Cloud (for free) and get to experimenting.