
What do teams of data engineers do for fun when they escape to the Mediterranean coast of Turkey?
Why, they head to the basement to develop new apps and projects to optimize data pipeline efficiency, of course.
At Zyte’s 180-person Antalya retreat this month, Zytans split into seven teams for a workshop with one brief: “Combine Zyte data with any public API (news, maps, weather, etc) and present the most creative output.”
Spoils of the hackathon
When they emerged into the sun, here’s what they had made.
1. ZyBounty: Automatic security vulnerability discovery
Every day, up to 40 cool new products are listed on ProductHunt. Sadly, industry research shows about a fifth of web apps out there have critical vulnerabilities or exposures (CVEs).
What if we could automatically scan new products and proactively alert their owners to any risks?
ZyBounty checks websites’ headers for fingerprints matching a database of known vulnerabilities, then discovers security mailboxes for each affected site and drafts a helpful tip-off.
This project demonstrated how automated web data extraction can be used to create a more front-footed approach to cybersecurity.
Team 1: Paweł Miech, Jordi Yherla, Peter Malits and Chanaka Jayamal.

2. Restaurant Menu Scraper: Structured Data from Unstructured Menus
Barcelona has some pretty fantastic food offerings. But what if you wanted to have every single Catalan restaurant menu item at your fingertips?
One group built a web scraping application that extracts restaurant menu data from any geographical location, to provide market insights on pricing, brand presence, and cuisine trends. Restaurant Menu Scraper includes:
Restaurant search spider: Searches for restaurants in a specified location and extracts basic information.
Menu parser spider: Extracts menu data from HTML pages, PDFs, or images using LLM-powered extraction.
Zyte API integration: Leverages Zyte API for reliable scraping with browser rendering and automatic extraction.
The team even built a whole front-end interface onto all that data.
Now they know exactly where to buy the cheapest beer in the “City of Counts”.
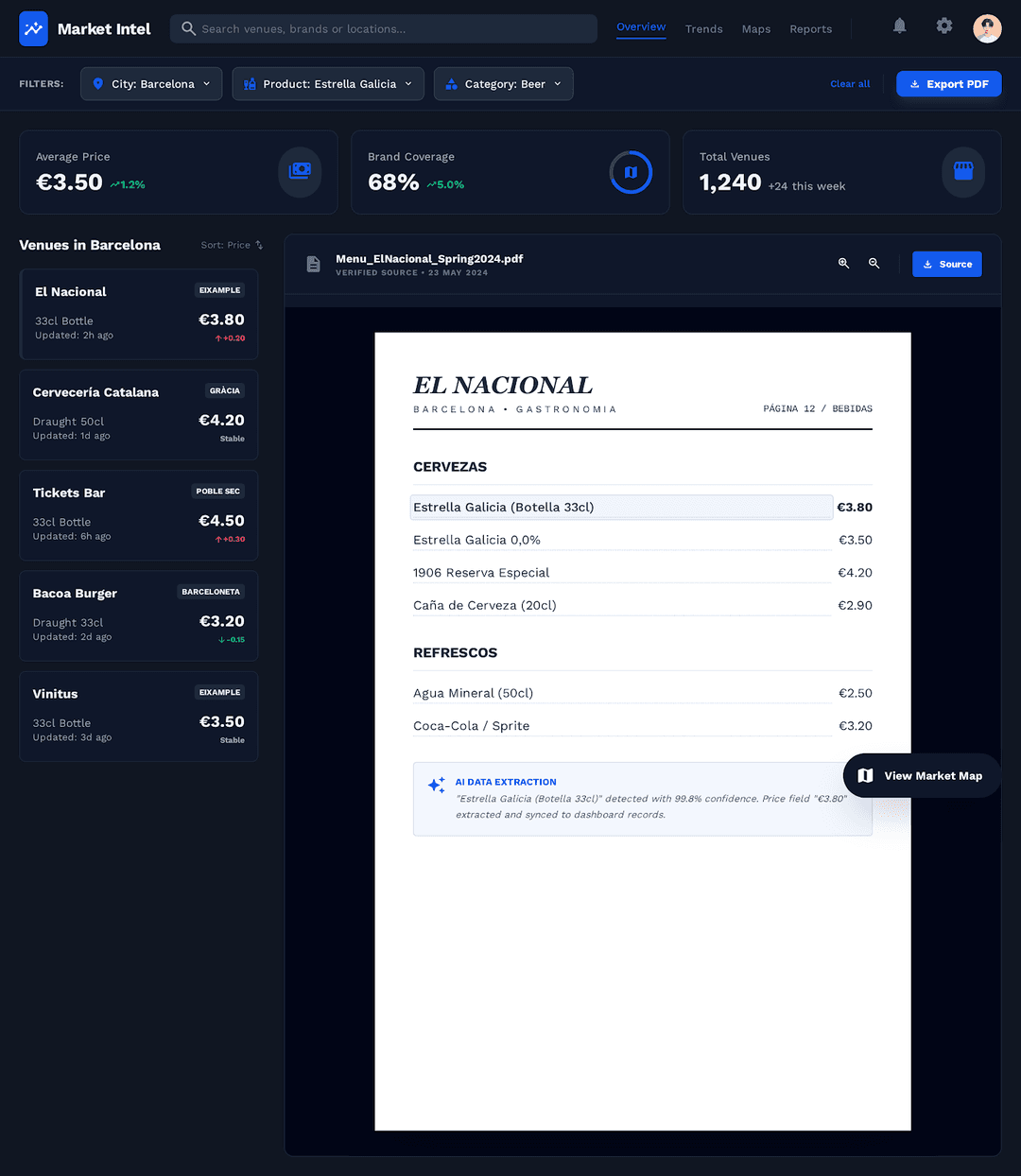
Get the GitHub repo now.
Team 2: Kenny Aires and Manuel Facio.
3. E-commerce comparison tool for price-conscious shoppers
An e-commerce product comparison engine was the focus of another team.
Their application would help users find the best prices for products online.
It used the Zyte API to first search for a product on the web and then to extract detailed information from the product pages in the search results. The application then presents the user with a ranked list of products based on price.
Product price comparison and aggregation is a popular use case for web data, so this project put the Zytans right into the shoes of many customers.
The team also planned to add features like historical price tracking and user alerts, showcasing how web data can be used to create practical tools for consumers.
Team 3: Renato Castro, Jose Yamil Maud, Lucas Oliveira and Emmanuel Rondan.

4. Zyte API auto-complete settings: Improving the developer experience
One team focused on improving the developer experience of Zyte API itself.
Their idea was to create a feature that would automatically suggest the best API settings for a given data extraction task.
This "auto-complete" feature would be integrated into Web Scraping Copilot (Zyte’s AI-powered scraping extension for Visual Studio Code) and into Zyte API’s own, web-based IDE, providing developers with real-time guidance on how to configure the API for optimal performance.
This project highlights the importance of developer experience and how tools can be built to make powerful APIs easier to use.
Team 4: Marcos Ribeiro and Aamir Mumtaz.
5. Historical Data Cache: Trading freshness for affordability
One team addressed an issue familiar to many data engineers - redundant data extraction, where data-gatherers repeatedly scrape the same pages for non-time-critical tasks like testing or market research.
Routinely scraping the same, unchanging data can be a waste of money. That’s why many people like to optimize their requests.
The team’s solution was a "Historical Data Cache," a feature that would selectively store data extracted via the Zyte API in a centralized data warehouse.
By adding a simple parameter to their API call (e.g., history=true), users could opt to receive the most recent cached version of the data, instead of initiating a new scrape. This approach offers a trade-off - while the data isn't guaranteed to be live, it can be delivered much faster and at a significantly lower cost, making it ideal for use cases where real-time freshness is not a primary concern.
Team 5: Lucas Franco de Queiroz, Filippo Petroli and Vivek Kushal.

6. SharedNetCache: Intelligent caching for multi-client pipelines
Another team developed "SharedNetCache," a dynamic caching solution designed for multi-client scraping environments.
This system introduces a centralized caching layer that stores raw HTTP responses and their scrape times.
A key feature is that crawlers can declare themselves "cache-aware" and specify a maximum acceptable age for the data they request. When a request is made, the system first checks the cache.
If a sufficiently fresh version of the data exists, it's returned immediately at no Zyte API cost. If not, a new scrape is performed, and the cache is updated.
This intelligent approach reduces redundant API calls while still giving clients control over data freshness.
Team 6: Muhammad Shafiq and Adnan Awan.
7. Survey completion by voice
Do you hate filling in surveys? One workshop team finds the task so laborious, it invented a time-saver.
Participants used Zyte API to download a target survey web page, then used an LLM to parse the questions into a chat interface. Using text or voice, a user could input responses in a natural conversation.
From there, the team’s script figured out how to map conversational responses back to the survey fields and used Zyte API’s browser actions to fill in those fields, after validating accuracy by taking a screenshot.
Team 7: Hamza Ali, Diego Rodrigues, Diogo Suguimoto and Fabián Canobra.

Creativity and data
Not everything here will necessarily go into full production.
But the Zyte API Hackathon in Turkey provided a valuable opportunity for developers to stretch their legs, to get creative, to experiment with the Zyte API and build practical applications.
The projects that emerged from the event demonstrate the wide range of use cases for web extraction, from consumer-focused tools to developer utilities - from finding a fresh beer to returning fresh data.
Zyte API
The ultimate API for web scraping. Avoid website bans and access a headless browser or AI parsing.





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
