A couple of weeks ago I published a walkthrough of my agentic coding setup, the plan-first discipline, the four-agent team, the model routing, the CLAUDE.md files that teach agents to remember between sessions. I stand by every word of it, and yet parts of it already read like a snapshot of a moving target, because that is the pace of the agentic AI world right now: Claude Fable 5 shipped on Tuesday, June 9, 2026. New primitives for autonomous work seem to arrive with every release, and workflows that felt cutting-edge in May, like babysitting a pull request while an agent chews through review comments, are quietly becoming things you design once and then stop doing by hand. The ground is moving under all of us, and it is moving weekly.
Then a clip went viral that put precise words to the shift. Boris Cherny, the creator of Claude Code at Anthropic, said in a recent interview: "I don't prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops." That is not a throwaway line from a futurist; it is the person who builds the most widely used agentic coding tool describing how he actually works, someone who by his own account went a month without opening an IDE while Claude Code wrote every line across 259 pull requests. He no longer prompts the model, he builds loops around it, and the uncomfortable, exciting implication for the rest of us is that increasingly, neither should you.
Addy Osmani has given the practice a name: loop engineering. Instead of steering a model one prompt at a time, you design a system where the agent runs, gets graded against explicit criteria, revises, and repeats until the criteria pass, all without you touching the keyboard. You write the definition of done once. The loop does the rest.
I have been sitting with this for a few days, and the more I turn it over, the more convinced I am that web scraping is not just another domain where loop engineering applies. I think it is one of the best-fit domains there is, because the hardest part of building a good loop is something our community solved years ago. This is an opinion piece, so consider everything that follows an invitation to argue with me.
What loop engineering actually is
Strip away the buzz and a well-designed loop has three parts. There is a generator, the agent doing the work. There is an evaluator, a separate agent or program that grades the output against a rubric of checkable criteria. And there is the loop itself, which feeds the evaluator's report back to the generator until the rubric passes or a budget runs out.
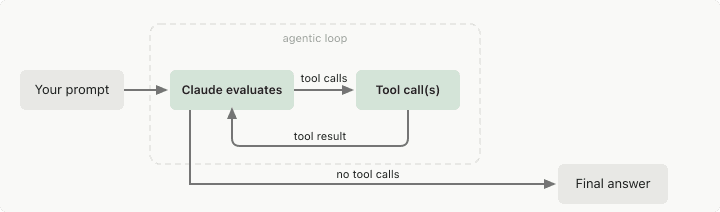
Source : https://code.claude.com/docs/en/agent-sdk/agent-loop
The one rule that everyone building these systems agrees on is that the generator must never grade its own work. Anthropic's engineering team wrote about this directly in their post on harness design for long-running tasks: when a single agent evaluates its own output, it confidently praises mediocre work, and "tuning a standalone evaluator to be skeptical turns out to be far more tractable than making a generator critical of its own work." Lance Martin at Anthropic reported the same pattern in his experiments with Fable 5, where verifier sub-agents running in independent context windows consistently outperformed self-critique, and where a rubric-driven loop let the model improve a training pipeline roughly six times more than the previous generation managed on the same task.
So the recipe is: write a rubric, separate the maker from the checker, and let the loop run. The whole pattern fits in one diagram, and it is worth a long look, because every idea in the rest of this piece is a variation of it.
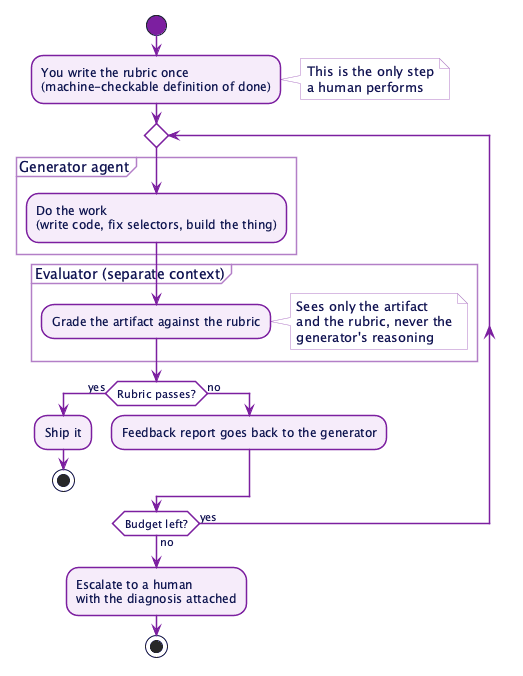
That diagram raises the obvious question of where the rubric comes from, because for most domains, turning "good output" into machine-checkable criteria is genuinely hard. For us, it is not.
Web scraping already has the hard part
Think about what a mature scrapy project with spidermon enabled looks like. There is a schema that every item must validate against. There are field coverage thresholds, because a run where only 60% of products have prices is a failed run no matter what the exit code says. There are expected item counts, error rate ceilings, and finish reason checks. In the Scrapy world we even have a dedicated framework for all of this, and I wrote about it earlier this year in my post on giving spidey-senses to your spiders with Spidermon.
Here is the reframe that I cannot stop thinking about: a Spidermon monitor suite is a rubric. Our community spent a decade encoding "what good data looks like" into machine-checkable criteria, because silent failure is scraping's oldest enemy, the spider that runs green for three weeks while quietly shipping garbage. We built the evaluator long before we had a generator capable of acting on its feedback. Every other field adopting loop engineering has to invent its definition of done from scratch. We just have to plug ours in.
The missing piece was never detection. It was what happens after detection, which until now was a human reading an alert, opening the site, sighing at the redesign, and rewriting selectors. Models like Fable 5, which Anthropic says can work autonomously far longer than any previous Claude model, are finally good enough to sit inside that gap. John Rooney saw early versions of this pattern when he built scraping agents for 30 days, and the lesson that stuck with me from his series is that agents fail not from lack of capability but from lack of structure around them. Loops are that structure.
The smallest self-healing spider I could build
I wanted to feel the shape of this before writing about it, so I built the most minimal version possible: a 20-line spider, a deterministic rubric, and a shell loop. No framework, no orchestration platform, nothing you could not reproduce in ten minutes.
The rubric is plain Pseudo code that reads items and exits nonzero with a report when quality drops:
1REQUIRED = ["name", "price", "url"]
2MIN_ITEMS = 5
3MIN_FILL_RATE = 0.95
4
5items = [json.loads(line) for line in sys.stdin if line.strip()]
6failures = []
7
8if len(items) < MIN_ITEMS:
9 failures.append(f"item count {len(items)} < {MIN_ITEMS}")
10
11for field in REQUIRED:
12 filled = sum(1 for i in items if i.get(field))
13 rate = filled / len(items) if items else 0.0
14 if rate < MIN_FILL_RATE:
15 failures.append(f"field '{field}' fill rate {rate:.0%} < {MIN_FILL_RATE:.0%}")The loop runs the spider, grades it, and on failure hands the report to Claude Code in headless mode with permission to read the page and edit the spider, then grades again:
1for attempt in 1 2 3; do
2 report=$(python3 spider.py | python3 rubric.py)
3 if [ $? -eq 0 ]; then
4 echo "$report" && exit 0
5 fi
6
7 claude -p --allowedTools "Read Edit" <<PROMPT
8The spider in spider.py failed its data quality rubric. Report:
9
10$report
11
12Read site/current.html, find why extraction fails, and fix the
13selectors. Do not change the output schema or modify the rubric.
14PROMPT
15done
16
17echo "Still failing after 3 attempts. Escalating to a human."Then I simulated a site redesign by swapping in a rewritten version of the page, with every class renamed and the structure reorganized. The spider's fill rate dropped to 0% across all three fields, the loop kicked in, and Claude diagnosed the markup change, mapped each old selector to its new equivalent, and the rubric passed on the first healing attempt.
One detail from the run delighted me. The healing agent tried to verify its own fix and was denied permission to execute anything, so the independent rubric re-run in the outer loop was the only judge of whether the patch worked. The maker-checker separation that Anthropic recommends was not something I prompted for. It fell out of the loop's structure. That is the whole point of loop engineering: the guarantees live in the harness, not in the model's good intentions.
A toy, obviously. The page was local, the redesign was synthetic, and three attempts against a fixture is not production engineering. But the shape is real, and the shape is what I want to talk about.
Scaled up honestly, with real scheduled jobs, an independent evaluator, capped attempts, and memory that compounds, the same shape becomes the architecture I keep coming back to:

Loops I want to see the community build
This is the breadth-first part, and the reason I wrote this piece. None of these are tutorials. They are shapes I think are now buildable, and I would genuinely love to see people run with them before I get to all of them myself.
Self-healing spider fleets
The demo above, scaled honestly: a monitor failure on a scheduled job triggers a healing agent that receives the failure report, the cached HTML from the last good run, and the current page. It patches the spider, an evaluator re-runs it against sample URLs, and only a passing grade deploys. Everything else escalates to a human with the diagnosis already written. The rubric is your existing monitor suite, which means teams running Scrapy Cloud with Spidermon already have the trigger and the grader in place.
Spider factories with a definition of done
Generation, not just repair. Instead of prompting an agent to "write a spider for this site," you hand it a goal: extract this schema from these 100 sample URLs with at least a 95% fill rate on every required field. The agent drafts, runs, reads its own fill rates, and iterates, and it does not get to declare victory, because the evaluator holds the rubric. This turns spider development from a conversation into a batch job.
Per-site memory that compounds
Lance Martin describes a memory progression that strong models complete in a loop: fail, investigate why, verify the diagnosis, distill it into a general rule, and consult that rule next time instead of re-deriving it. Map that onto fleet maintenance and you get per-site dossiers: "prices render via JavaScript after scroll," "this storefront migrated platforms in March," "the JSON API behind this listing page is more stable than the HTML." Every healing cycle deposits a lesson, and future cycles start by reading the dossier. Run a consolidation pass across the fleet periodically and cross-site patterns emerge, like a dozen sites sharing a storefront template that all break the same week. That is a scraping team's tribal knowledge, made durable and queryable.
Cost-aware escalation loops
Scraping has a dimension most agent domains lack: every retry has a price tag, and the difference between an HTTP request and a headless browser render is a multiple, not a rounding error. A well-designed loop should climb the escalation ladder only when the evaluator confirms the cheaper tier actually fails, and should record the cheapest configuration that passes the rubric as the new default. The loop optimizes for cost per record, not just for fill rate. I find this idea particularly exciting because it points at loops that do not just maintain quality but actively drive your unit economics down while you sleep.
Plausibility graders that catch the lies
Schema validation catches missing data. It does not catch plausible garbage: prices scraped from the related-items carousel, descriptions truncated at the first comma, currency symbols that quietly changed. A second-tier evaluator, an LLM judge that samples a handful of records per run and compares them against the live page, catches the failure mode that has burned every scraping team I have ever talked to. This grader is cheap because it samples, and it only needs to answer one question: would a human looking at this page agree with this record?
Schema drift scouts
Loops that propose, rather than repair. An evaluator that notices recurring data on pages that your schema does not capture, a new "fulfilled by" field, a sustainability badge, a member price, and files a suggested schema addition with sample evidence. Your extraction quietly keeps up with what the web is publishing instead of freezing at whatever the schema looked like on day one.
Coverage loops for discovery
Item-level quality is one rubric, but corpus-level coverage is another: did we find all the products, all the locations, all the listings? A discovery agent that expands the crawl frontier, graded on coverage against known totals and on duplicate rate, turns the vaguest part of scraping, "are we even seeing everything?", into a number that a loop can push upward.
How I plan to use it
My own starting point is the rubric side, because I think that is where the leverage is. I already maintain a Claude skill that generates Spidermon monitor suites from sample items, which means the grading criteria for any spider can themselves be generated in minutes, and in my agentic coding setup I have been gating agent-written scraping code on objective metrics like fill rate for months without calling it loop engineering. The next step for me is wiring the healing loop into real scheduled jobs, with Zyte API handling access so the loop's failures are genuinely about extraction logic rather than about blocking, and Spidermon actions as the trigger. That experiment deserves its own write-up with real numbers, costs, and the inevitable embarrassing failure cases.
One caution belongs here, and it is the part of the trend I think our industry needs to hold onto hardest. Osmani ends his piece warning against cognitive surrender, accepting whatever the loop produces because it is comfortable, and scraping has a version of this with sharper edges than most fields: an autonomous loop that patches spiders can also patch its way into data you did not intend to collect, from places you did not intend to touch. Compliance review, robots and terms awareness, and the judgment about what should be scraped at all do not go inside the loop. They stay with us. Build the loop, but stay the engineer.
Am I wrong?
I have shown you the smallest possible version and sketched seven bigger ones, and I am certain the list is incomplete, which is the point of publishing it. If you run spiders in production, you already own the hardest artifact in loop engineering, a battle-tested definition of done, and the only question is what you connect it to. So tell me: which of these loops would you trust in production first, and which one would you never let run unattended? I am easy to find, and I would rather be corrected in public than confident in private.
Find my repo here: https://github.com/zytelabs/webscraping-loop-engineering-demo





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
