
Author
John Rooney
Developer Engagement Manager
John is the Developer Engagement Manager at Zyte, working closely with the community, creating content and helping developers learn web scraping, Zyte products an much more. He has spoken at Extract Summit's and also creates the workshop's for the events.

Podcast Ep08 - Scrapy, Python and mushroom soup
Scrapy's core handles crawling well and deliberately leaves almost everything else out: no bundled browser, no opinion about how you shape your data, no built-in answer for every anti-bot wrinkle. What it gives you instead is a clean way to add those things at the edges, exactly when you need them and never before.

The missing middle ground in scrapy-playwright just got filled
You can now choose which Python browser library you want to use with scrapy-playwright. I go through why this is a huge deal for the right scraping demographic.

AI generated these Scrapy projects - why I won't ship them
What happens if you let AI create a Scrapy project from just a simple prompt? Here's what I got and what I had to fix.
The harness matters more than the model - Podcast EP07
"The model is the engine — but the harness is everything else." In Episode 7, we dig into why the infrastructure layer around your AI model matters more than the model itself, rank the best models available right now, and ask whether the open-weighted revolution is about to make frontier subscriptions obsolete.

Building a self-hosted browser scraping service (is it more hassle than its worth?)
If you want to understand exactly how a browser scraping service works at the infrastructure level, or you have a steady workload that you want running on hardware you already own, building one yourself teaches you things that matter. Here's how I did it
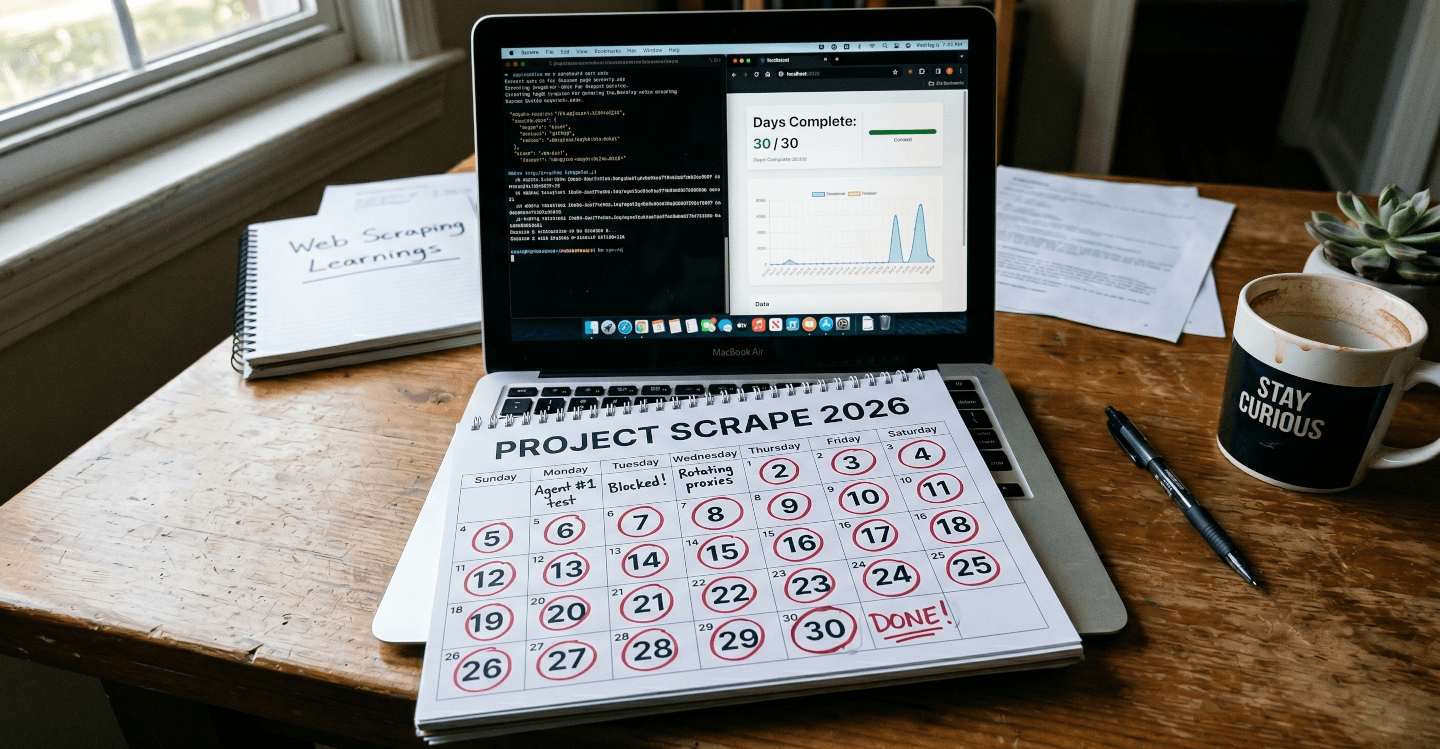
I built scraping agents for 30 days - here’s what I learned
For the last 30 days, I did one thing almost exclusively: I built scraping systems with AI agents, from the ground up, across real targets, with real deadlines. Not prototypes designed to impress in a demo, not isolated experiments running against a toy website, but production-grade pipelines that needed to ship and keep running.

How to parse HTML tables into structured data (CSV/Excel)
In this guide, you'll learn three things: how HTML tables are actually structured (so the parsing makes sense), how to extract clean tabular data using Python, and how to export it to CSV or Excel

Supercharging web scraping with Claude skills
Learn how Claude skills can automate HTML fetching, AI parsing, selector generation, and structured data extraction to build faster, smarter web scraping workflows.

Screenshot webpages with this Claude Skill and Zyte API

0% Hallucination? RAG + Web Scraping (Step-by-Step)
A data scientist's guide to stress-free product scraping
As a data scientist, your job is to find patterns, build models, and generate insights. To do that, you first need to reliably acquire web data. Competitor pricing, product specifications, consumer reviews - you name it, data scientists need it.
Why Python Requests gets "403 Forbidden"
If you’ve had your HTTP request blocked regardless of using correct headers, cookies, and good IPs, there’s a chance you are running into one of the simplest forms of blocking, and one of the most confusing for beginners.

Generate HTML Parsing code the right way with Scrapy & Web Scraping Copilot

API-first scraping: Extraction for the modern web
This is the "API-first" method, a workflow that turns brittle, complex parsing jobs into clean, reliable, high-velocity JSON pipelines.

Hybrid scraping: The architecture for the modern web
Learn how hybrid scraping combines headless browsers and lightweight HTTP clients to bypass JavaScript challenges efficiently. Reduce RAM usage, improve speed, and scale your web scraping pipelines with session reuse and TLS fingerprinting.
Your business doesn’t care about scraping - it cares about data
Web scraping isn’t the competitive advantage it used to be. Learn why shifting to a scraping API helps engineers reclaim time, reduce maintenance, and focus on delivering reliable data.

Zyte API Sessions - flexible cookie management maintaining control

How to transfer browser cookies to an http session when web scraping

How to create a Docker container with Scrapy and PostgreSQL

Swiss Army Knife Docker Container for Web Scraping

Your Web Scrapers Keep Getting Blocked. Here's Why

Making Your First Zyte API Request

Introducing Web Scraping Copilot for VS Code.

Why Does No one use this KILLER Scrapy Addon?

Web Scraping API's are cheaper than Proxies?

How I use AI and MCP to Scrape Data

Should you BUY your WEB DATA, or Write Code?

Stop Scraping RAW HTML into your LLM. Try our new feature

How I go from Zero to Data in 10 minutes with Scrapy

Gemini 3.0 Pro Code Gen With Web Scraping Copilot

Build Your Own Price Drop Notifier (Zyte Auto Extract + IFTTT Mobile Alerts)
Hybrid Scraping: The Architecture for the Modern Web

Modern Web Scraping starts with THIS.

3 Rules of Modern Web Scraping
The Modern Scrapy Developer's Guide (Part 3): Auto-Generating Page Objects with the Web Scraping Copilot
In this guide, we'll show you how to use Web Scraping Copilot (our VS Code extension) to automatically write 100% of your Items, Page Objects, and even your unit tests.
The Modern Scrapy Developer's Guide (Part 2): Page Objects with scrapy-poet
In this guide, we'll fix this by refactoring our spider to a professional, modern standard using Scrapy Items and Page Objects (via crapy-poet). We will completely separate our crawling logic from our parsing logic.
The Modern Scrapy Developer's Guide (Part 1): Building Your First Spider
In this definitive guide, we will walk you through, step-by-step, how to build a real, multi-page crawling spider. You will go from an empty folder to a clean JSON file of structured data in about 15 minutes
The Modern Web Scraping Method You NEED to Know
Learn how to scrape data in json format from a websites API
Modern Scrapy for Developers
From SEO audits to market intelligence, scraping search engine results data can give you the insights you need to make smarter, faster business decisions.




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
