
Web scraping has long been viewed by the uninitiated as a brute-force exercise in parsing HTML. It is a misconception born from the early days of the static web, where a website was simply a collection of files resting on a server, waiting to be read.
In that era, the standard workflow was simple: you fired up a script, downloaded the document, and used a library like Beautiful Soup or Cheerio to hunt for
But if you are applying this logic to a modern e-commerce platform, a dynamic Single Page Application (SPA), or a complex travel aggregator, you are fighting a losing battle. You are building on quicksand. Modern frontends are volatile; a minor A/B test or a routine CSS update by the site's engineering team will shatter your selectors and bring your data pipeline to a halt.
The battle for scalable data access is no longer about better parsing; it is about architectural understanding.
This is the "API-First" method—a workflow that turns brittle, complex parsing jobs into clean, reliable, high-velocity JSON pipelines.
The Paradigm Shift: From Rendering to Retrieval
To understand this method, you must understand the architecture of the modern web.
Today’s sophisticated websites rarely serve fully populated HTML to the user. Instead, they utilize a "Client-Side Rendering" (CSR) or "Hydration" architecture. When you visit a product page, the server sends a lightweight skeleton—a template. Once that template loads in your browser, a piece of JavaScript executes, reaches out to a backend API, fetches the data (usually in JSON format), and dynamically paints the content onto the screen.
The novice scraper waits for the painting to finish and scrapes the paint. The expert scraper goes right to the bucket.
By targeting the API directly, you bypass the presentation layer entirely. You don't care about the DOM structure, the CSS classes, or the layout. You only care about the structured data source. This approach is faster, cleaner, and significantly more resilient to frontend changes.

Phase 1: The Discovery (XHR Filtering)
The discovery phase is an investigative process. You are looking for the "Source of Truth."
Open your target website in Chrome or Firefox, right-click, and Inspect the page. Navigate to the Network tab. This is your command center. By default, this tab is a chaotic firehose of information—loading images, tracking pixels, font files, and CSS stylesheets.
You need to filter the noise. Click the Fetch/XHR filter. Now, you are seeing only the data traffic.
Trigger the request. Refresh the page, or if the site uses infinite scrolling, scroll down. Watch the "Waterfall" of requests. You are looking for specific patterns:
File Types: Look for requests returning application/json or graphql.
Naming Conventions: Developers are humans; they name endpoints intuitively. Look for v1, api, search, catalog, inventory, or query.
Payload Size: Data-rich responses are often larger than the tiny status pings sent to analytics servers.
The "Golden Endpoint"
When you identify a candidate, click "Preview." If you see HTML, keep looking. If you see a nested JSON object containing prices, SKU numbers, image URLs, and stock levels, you have struck gold.
Often, this data is richer than what is displayed on the screen. A product card might show "$19.99" and "In Stock," but the underlying JSON object might reveal:
"Pro Tip: GraphQL endpoints are the holy grail of API scraping. If you see a request going to /graphql, inspect the payload. You can often modify the query structure to request more data fields than the website itself asks for, essentially asking the database for exactly what you need."
Once you have the URL, verify its utility. Test it in your browser’s address bar. Change the parameters. If the URL ends in limit=20, change it to limit=100. If it says page=1, switch it to page=2. If the JSON response adapts, you have a functional, direct line to the database.

Phase 2: The "Clean Room" Isolation
Finding the endpoint is only step one. The next challenge is "Clean Room" isolation: determining the minimum viable request required to access that data programmatically, outside the browser context.
Simply copying the URL into a Python script will usually fail. The server expects the request to come from a trusted environment (a browser), not a script. To bridge this gap, we use a process of subtraction.
Copy as cURL: Right-click the successful request in DevTools and select "Copy as cURL".
Import to Client: Paste this into an API client like Postman, Bruno, or Insomnia.
The Baseline Test: Hit "Send." It should return a 200 OK because you are replicating the browser perfectly, including every cookie and header.
Now, you play the "Load-Bearing" header game. Efficient scrapers don't send 2KB of bloatware headers. You want to strip the request down to its skeleton to understand what the server actually validates.
Start unchecking headers one by one and resending the request:
The Cookie: This is the most critical test. If you remove the Cookie header and the request still works, you have found a public API. You can scrape this endlessly with zero overhead. However, on most commercial sites, removing the cookie will trigger a 401 Unauthorized.
The Referer & Origin: Websites often check these headers to ensure the API request originated from their own frontend. If you remove them, the request may fail. This is a common Cross-Site Request Forgery (CSRF) protection mechanism acting as a scraper blocker.
The User-Agent: Some APIs block requests that identify as "python-requests" or "curl".
Eventually, you will arrive at the "Skeleton Key": the absolute minimum set of headers required to get the data. Usually, this is a specific User-Agent, a Referer, and a session-bearing Cookie.

Phase 3: The Infrastructure Trap (The "Bonded" Token)
This is where the theoretical simplicity of API scraping collides with the brutal reality of modern anti-bot systems.
A developer will often take their "Skeleton Key"—the correct URL, the correct headers, and a valid Cookie—paste it into their code, and immediately receive a 403 Forbidden or 429 Too Many Requests.
Why? You have the credentials. Why is the door locked?
The answer lies in Cryptographic Binding and TLS Fingerprinting.
The IP Link
In an analysis of modern scraping targets, we see a rising trend where API endpoints enforce a strict, cryptographic link between the Auth Token and the IP address used to generate it.
When you browsed the site to get the cookie, you used your home IP (or office IP). The server issued a token bound to that IP. When you run your scraper, it might be running on a cloud server (AWS, GCP) or routing through a proxy. The server sees a valid token coming from a different IP than the one that minted it. It flags this as a "Session Hijack" attempt and blocks the request.
**
The Expiry Clock**
Furthermore, these tokens are ephemeral. Modern security architectures (like JWTs) are designed to expire quickly—sometimes in as little as five minutes. If you are scraping a catalog of 10,000 products, your static token will die before you reach product #50.
**
The TLS Handshake**
Beyond the headers, many anti-bot vendors analyze the TCP/TLS handshake itself. A Chrome browser negotiates a TLS connection differently than a Python script. It uses different cipher suites and elliptic curves. This "JA3 Fingerprint" acts as a DNA test. Even if your headers say "I am Chrome," your handshake screams "I am a Python script."
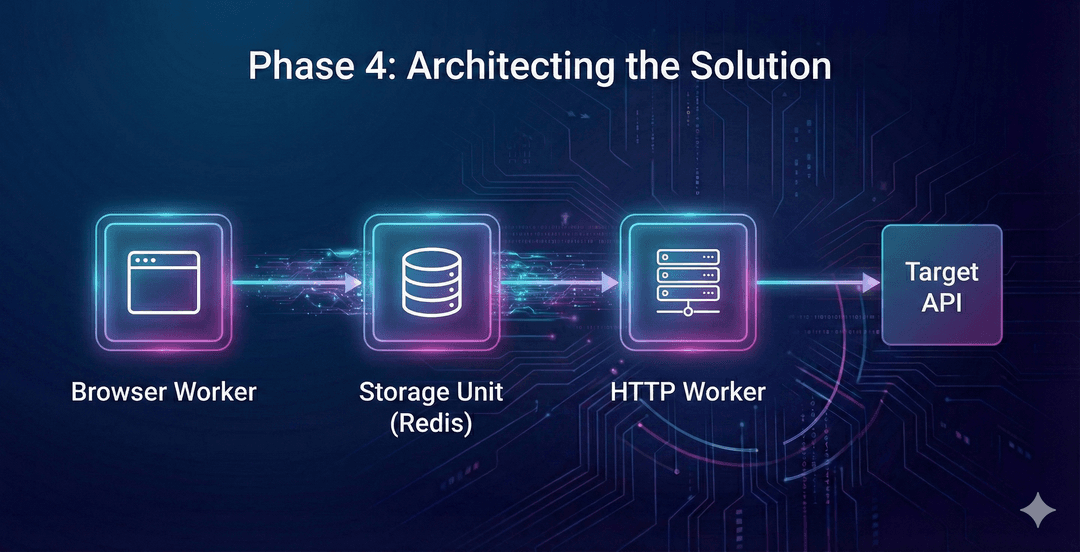
Phase 4: Architecting the Solution (The Hybrid Model)
To operate at scale against these defences, you cannot simply write a script. You must engineer a system.
We have found that the only reliable way to bypass these checks without constant manual intervention is to implement a Hybrid Architecture. This approach splits the scraping process into two distinct roles: The Authentication Worker and the Data Worker.
1. The Storage Unit (State Management)
You need a centralised "brain" to manage state—typically a fast key-value store like Redis. This database stores a "Session Object" containing:
The active Auth Token (Cookie).
The specific Proxy IP used to generate that token.
The User-Agent string associated with that session.
The created_at timestamp.
2. The Browser Worker (The Heavy Lifter)
This is a headless browser (using tools like Puppeteer, Playwright, or specialized stealth browsers like Nodriver/Camoufox). Its job is not to parse data.
Its job is to visit the site, execute the heavy JavaScript, pass the anti-bot checks, and wait for the session cookies to be set. Once the cookies are generated, it extracts them, bundles them with its current IP address, and pushes this "Session Object" to the Storage Unit.
3. The HTTP Worker (The Speedster)
This is your actual scraper. It does not use a browser. It is a lightweight HTTP client (like Python's httpx or Go's net/http).
Before every request, it queries the Storage Unit. It pulls the valid Token and the exact same Proxy IP used by the Browser Worker. It then hits the API directly.
Because it replicates the identity created by the browser, the server accepts the request.
4. The Rotation Logic
You need logic that monitors the health of the session.
Is the token older than 5 minutes?
Did we just get a 401 error?
Is the IP blocked?
If any of these flags are raised, the system pauses the HTTP Worker, triggers the Browser Worker to "refresh" the session (generate a new token/IP pair), updates the Storage Unit, and then resumes scraping.
The Hidden Overhead
Suddenly, your "simple" scraping job has evolved into a complex microservices architecture.
You are no longer just scraping data. You are managing a Proxy Rotation System to ensure the Browser and HTTP workers share the same exit node. You are managing a Browser Fleet to handle the CPU-intensive task of token generation. You are writing complex error-handling logic to manage race conditions between token expiry and request execution.
This is the hidden tax of the API-First approach. The code to fetch the data is minimal—often just one function. But the infrastructure required to maintain the identity needed to access that data is massive.
Fabien Vauchelles, creator of Scrapoxy, noted in a recent discussion that the goal of modern anti-bots is not just to block, but to "raise the cost to play." By forcing you to run headless browsers and manage complex state, they make scraping computationally expensive and engineering-heavy.
The Zyte Solution: Abstracting the Complexity
This is why "just scraping the API" is harder than it looks. You end up spending 80% of your time managing infrastructure and only 20% analysing the data.
At Zyte, we believe developers shouldn't have to build a browser farm just to get a JSON response.
We have abstracted this entire "Hybrid" architecture into a single API call. Zyte API handles the browser fingerprinting, the AI-driven unblocking, the IP management, and the session rotation automatically.
When you send a request to Zyte API, our internal systems:
Analyse the target site's protection level.
Spin up a browser if necessary to generate the required cryptographic tokens.
Seamlessly hand off those credentials to an optimised HTTP layer.
Deliver you the clean response.
You simply send us the URL. We handle the "arms race" in the background, delivering you the data without the infrastructure headache.








_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
