How To
Articles from the Zyte blog about How To.

Harness Engineering #3- Headless mode: the minimal agent harness
What's the smallest harness that still works? Turns out it's already sitting inside almost every coding agent you have installed — headless mode: same loop, tools, and reasoning as the interactive agent, minus the human in the chair. We point it at a web page and pull clean, structured data out the other end in about ten lines.

The Modern Web Scraping Method You NEED to Know
Learn how to scrape data in json format from a websites API

Inside Zyte's System Design Process: How We Build Scalable, Reliable Solutions
Explore Zyte’s approach to building scalable and reliable systems through PRDs, technical requirements, solution evaluation, and real-world design insights.
Geo-blocking solutions for digital shelf analytics
Zyte API offers a powerful solution for digital shelf analytics companies to overcome geo-blocking challenges.
Extract localized data with Zyte API’s extended geolocation
High quality web data extracted from localized websites can be tricky and expensive. We share how we solved geolocation issues with Zyte API’s extended geolocation.

The Scraper’s System Part 2: Explorer’s Compass to analyze websites
Learn about the scrapers system: Explorer’s Compass to analyze websites.
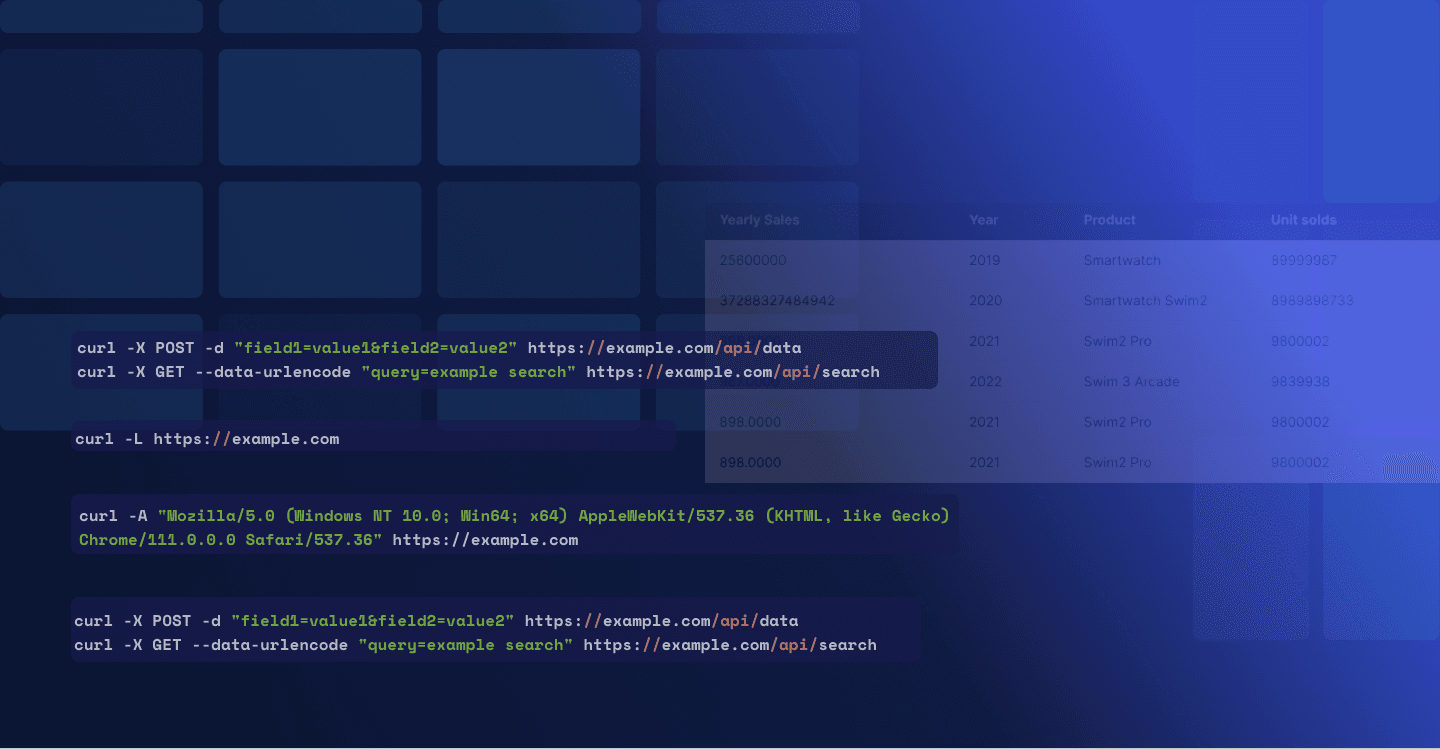
Use cURL for web scraping: A Beginner's Guide
cURL simplifies data collection from websites via its command-line interface, making it essential for APIs, file transfers, and web scraping.

Scrapy Cloud secrets: Hub Crawl Frontier and how to use it
Our scrapy cloud secrets help you deal with real cases that put your data extraction pipeline at risk. You have to be fully prepared for every scenario.
How Web Scraping and Graph Databases Can Power Recommendation Engines
I recently had the pleasure of participating in the third episode of Graphversation, a monthly live stream series that brings together graph experts and Neo4j enthusiasts for engaging and enlightening discussions about the captivating world of graphs.
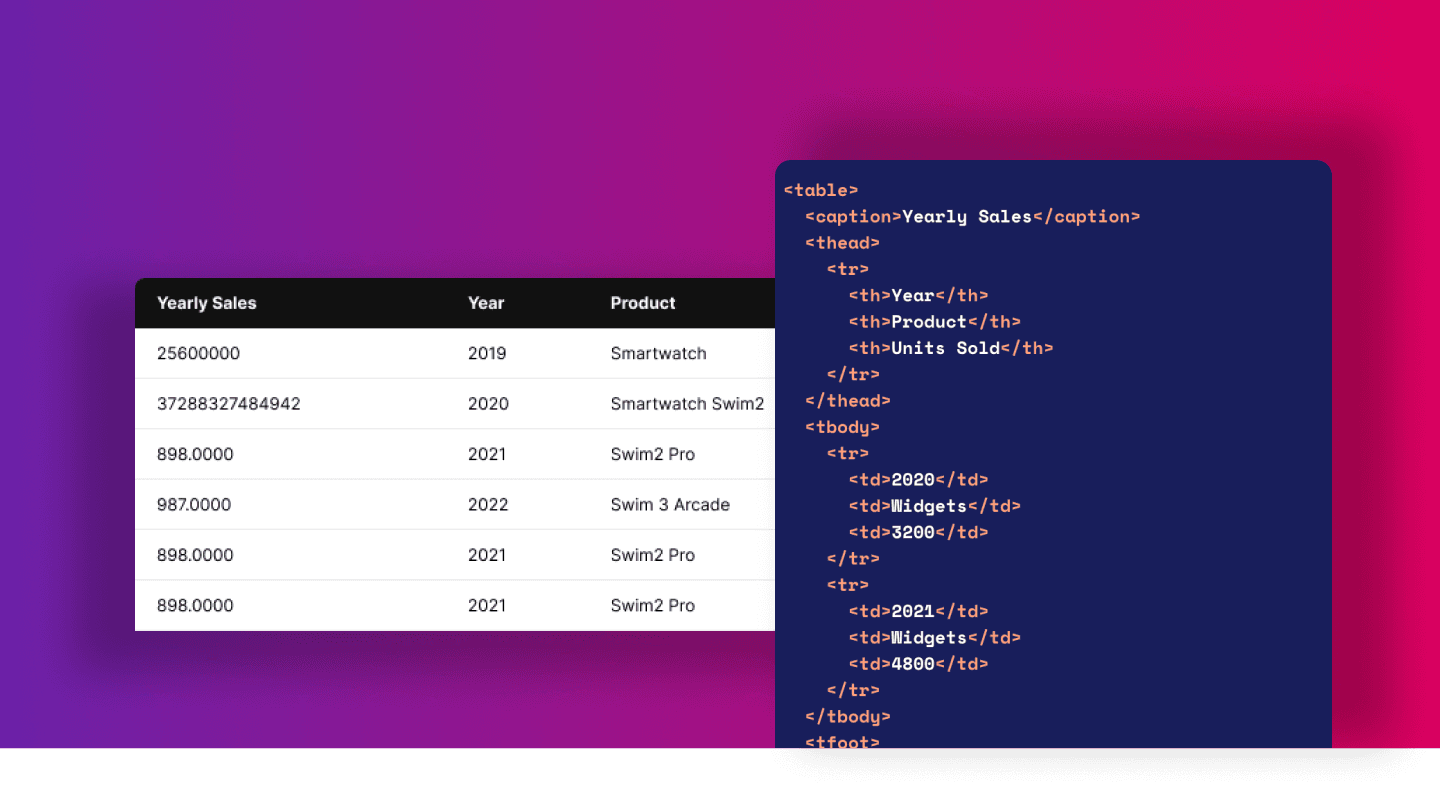
How to Extract Data From HTML Table
Learn how to extract data from a HTML table with step-by-step instructions. Get all the tips on extracting data from an HTML table in Python and Scrapy.
Storing and Curating Your Web Crawling Data
Web crawlers are becoming increasingly popular in the era of big data, especially now with the advent of Large Language Models (LLMs) such as ChatGPT and LLaMA. The sheer amount of data that is publicly available from the web has a wide variety of applications including market research, sentiment analysis, and predictive modeling.

4 simple Steps for effective Automated Data QA Process
Learn how to develop an automated data QA process. Improve your web data quality applying a process that communicates with all your internal system procedures.




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
