Are they agent designers for the messy web?
In the AI-agent version of web scraping, the user does not ask for a spider. They ask for an outcome: find these products, monitor these pages, compare these suppliers, build this dataset, keep this information fresh. The system then has to discover sources, access websites, navigate pages, extract information, validate results, and deliver structured data into a workflow. At first glance, that sounds like bad news for web scraping developers. If a user can ask for data in plain language, do developers become less important?
The opposite is more likely. The role is not disappearing -- it is moving up the stack.
Web scraping developers are becoming agent designers for the messy web. Not in the vague "draw a box around an LLM" sense, and not prompt engineers in the shallow sense. In web scraping, agent design means deciding what tools an agent can use, what sources it can trust, what schema it must satisfy, what evidence it must preserve, when it should retry, when it should escalate, and when it should stop.
Everyone may become an agent manager in some sense: assigning work, reviewing outputs, deciding what should stay human. Web scraping developers sit one layer deeper. They design the operating conditions that make an agent reliable on the live web. That distinction matters because the live web is not a clean API. It is an unstable, adversarial, inconsistent environment. The agent may execute parts of the workflow, but someone still has to design the workflow so the output can be trusted.
The hard parts move; they do not disappear
AI can make web scraping work faster to start. LLMs are already part of daily development work for many developers -- generating code, inspecting HTML, suggesting extraction logic, summarizing pages, classifying content, drafting tests, supporting QA. They are useful. They compress some of the mechanical effort.
But production web data still carries the same old problems:
- Sites change without warning
- Content moves between listing pages and detail pages
- Variants, reviews, locations, categories, and availability all require different crawl strategies
- Websites block, throttle, redirect, or render differently
- Data can be incomplete in ways that look plausible
- Customer schemas do not always match what a page naturally exposes
- Large crawls require scheduling, prioritization, monitoring, and maintenance
- Downstream systems expect consistency, not "mostly right"
AI does not remove those problems. It changes where they show up.
A demo can make the problem look like: can the agent scrape this page? In production, the real question is broader: can the system get the right data, from the right sources, at the right cadence, in the right structure, with enough evidence that someone can trust it? That is not only an extraction problem. It is a systems problem.
From scraper developer to web-data agent designer
Traditional web scraping work often begins with a known target and a known output. A developer studies the site, writes a spider, handles pagination, extracts fields, manages edge cases, monitors change, and maintains the system over time.
Agentic workflows introduce a different interface. The user may begin with intent -- "I need this kind of data from these kinds of sources" -- without knowing exactly what they want to solve a problem. The system may then have to discover where to go, choose how to access the site, decide what to extract, validate what it found, and recover when the path fails.
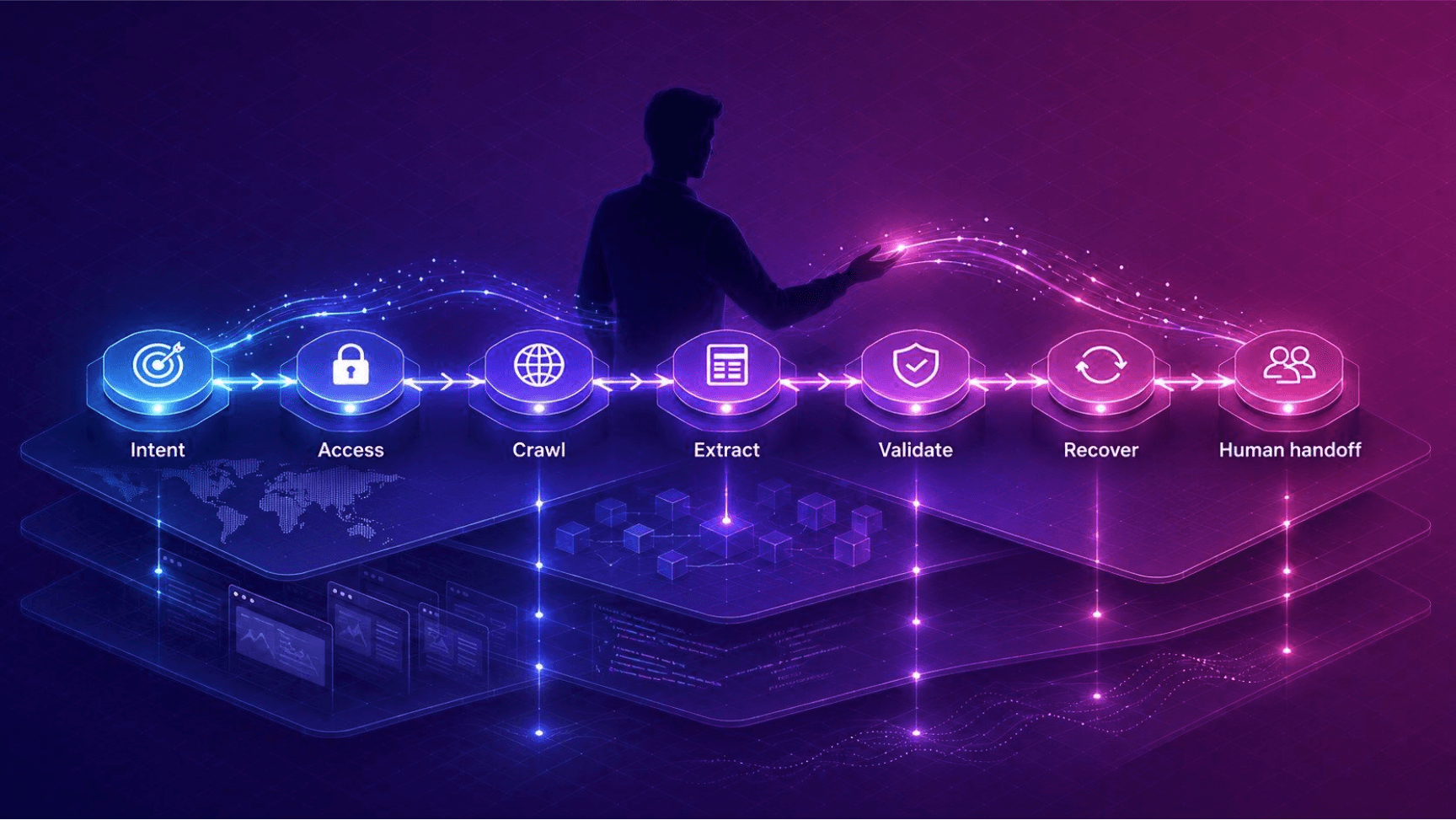
That makes the workflow look less like one scraper and more like a chain:
Discover → Access → Crawl → Extract → Validate → Recover → Hand off
Each step needs design. Discovery needs boundaries. Access needs reliability. Crawling needs strategy. Extraction needs schema. Validation needs criteria. Recovery needs policies. Handoff needs context.
This is where the developer's role expands. The question is no longer only "How do I extract this field from this page?" It becomes:
- What is the agent allowed to try?
- What context does it need before it acts?
- What does good output look like?
- How will we know if the result is incomplete?
- What evidence should be preserved?
- What should be automated now, assisted with review, or escalated to a human?
That is agent design. For a closer look at how this plays out at scale, see What multi-agent orchestration looks like in a large-scale web scraping project.
AI makes planning and review more important
In conversations with developers at Zyte, one theme came up repeatedly: LLMs are changing the mechanics of development, but they are making planning and review more important, not less.
Developers are using AI to accelerate implementation, generate code, create expected outputs, work with fixtures, inspect page structures, and support QA. Tools like Web Scraping Copilot -- Zyte's free VS Code extension -- are a practical example of this: AI handles the boilerplate of spider generation, while the developer stays in control of the code, the structure, and the decisions that matter. But the strongest developers are not simply delegating everything to the model. They are defining the task, shaping the context, reviewing the output, and deciding whether the result is good enough.
Julia Medina described the shift this way:
"Right now, it's more about understanding what you want to do and how you want the finished product to look in the end."
She also reached for a useful metaphor:
"We're more like leaders. We have this junior developer, or sometimes something with more seniority, in an agent doing what we told it to do. We are the ones reviewing that work."
That is the shift in miniature. The agent may produce the first version of the work, but the developer still owns the intent, constraints, review, and judgment.
This is also why the word "designer" matters here. If AI makes implementation cheaper, weak criteria become more expensive. It becomes easier to build the wrong thing quickly. Adding another feature, path, or automation step can look cheap in the moment, but every extra behavior creates something that needs to be understood, tested, monitored, and maintained. In an AI-assisted workflow, design judgment is not decoration. It is the brake, steering wheel, and map.
Crawling logic is where demos meet reality
A recurring misconception in AI conversations is that web scraping is mostly about extracting fields from a page. In real projects, extraction is only one layer.
Large-scale web-data systems often involve search pages, listing pages, product pages, detail pages, review pages, variants, categories, location-specific results, and customer-specific schemas. A system may not crawl every page every day -- it may need to prioritize subsets, store discovered URLs, refresh detail pages on a different cadence, and keep data delivery aligned with business requirements.
In that world, the hard part is often not "can we parse this HTML?" It is deciding how the data acquisition system should behave. What should be crawled daily? What can be refreshed monthly? Which pages reveal variants? What happens when a section of the site changes, or a source blocks, redirects, or returns partial content?
AI can help with parts of this -- proposing plans, generating first drafts, inspecting examples. But real websites contain more variation than a small prompt can hold. Akhter Wahab described the limit clearly:
"We try to write crawling logic with AI on a day-to-day basis, but it doesn't solve everything. It can give you a good picture, but it doesn't solve the real problem."
On the context problem specifically:
"A human may need to inspect 200 pages that are actually different before making a decision. With an LLM we might give it 10 or 20 URLs, and it's us who need to explain which pages are different."
That is a practical version of context engineering. The developer decides what the agent needs to see, what it should ignore, how much variation matters, and how its plan should be evaluated. The agent can help reason about a crawl, but the developer still has to understand the terrain. This is one of the core tensions explored in Why AI agents struggle with web scraping -- access and context problems don't disappear when you add a model; they just become the model's blind spots.
Prompt-to-data needs a trust layer
The most important question for AI web-data workflows may not be "can it extract?" It may be "why should we trust the result?"
Data quality has always been central to web scraping -- teams need to know whether the system collected the expected number of items, whether important fields are present, whether values are accurate, whether the data is clean, and whether it follows the agreed schema. AI makes this question more urgent because generated outputs can look convincing even when they are incomplete or wrong.
A trustable prompt-to-data system needs to answer questions about itself:
- Which sources were used?
- Was each page accessed successfully?
- Was any content blocked, missing, or rendered differently?
- How complete is the dataset?
- Which fields are below expected coverage?
- What schema did the system validate against?
- What evidence supports the extracted value?
- Which issues were automatically resolved, and which need human review?
This is where web scraping experience becomes especially valuable. Developers and QA teams already know that data quality is not a vague feeling -- it is built through requirements, schemas, coverage checks, hygiene checks, monitoring thresholds, manual review, and escalation workflows. Zyte has covered the mechanics of this in depth in Data quality assurance for enterprise web scraping, and tools like Spidermon exist precisely because monitoring and validation need to be designed in, not bolted on after the fact.
AI can become a QA copilot, but only if it has the right context: schema, source HTML, spider statistics, project configuration, prompts, examples, and prior decisions.
Tomasz Lesiak put it simply:
"A lot has changed, but not really much has changed. We still do our QA, we still do whatever we did five years ago, but now we have this automation layer that allows us to do so much more."
AI does not erase the QA discipline. It extends its reach. The future is likely one where agentic extraction and agentic verification evolve together -- where the web-data agent does not just fetch data, but helps explain whether the data is reliable.
The new job is boundary design
When people ask how much of web scraping will be automated, the answer is unlikely to be all or nothing. A more useful frame is three buckets:
Automate now. Repetitive, well-understood tasks where the cost of error is low and validation is straightforward. AI can help generate boilerplate, draft extraction logic, summarize pages, produce test fixtures, classify obvious cases, and speed up routine checks. Four sweet spots for AI in web scraping is a good starting point for thinking about where this automation actually earns its keep.
Assist, but keep human approval. Tasks where AI can produce a strong first pass, but a developer or QA person should review the decision -- crawl strategy, schema mapping, edge-case handling, ticket verification, diagnosing ambiguous data-quality issues.
Never automate without escalation. Situations where the system is uncertain, the source is sensitive, the business cost of error is high, or the data appears plausible but cannot be verified. In these moments, the best agent is not the one that keeps going. It is the one that knows how to stop, explain what happened, and ask for help.
This boundary-setting may become one of the most important skills in web-data engineering -- and it is also why "agent designer" is a better phrase than "agent manager" for this role. Management is about supervising work. Design is about shaping the conditions under which work can safely happen.
AI-agent builders need the messy web
The broader AI-agent ecosystem is moving quickly. Builders are experimenting with browser runtimes, tool-calling workflows, crawler integrations, MCP servers, agent skills, memory systems, and multi-agent patterns.
This matters for web scraping because many useful agents eventually run into the same requirement: they need current information from the open web, not just a clean internal API or a static document store. But live web access is messy. It requires infrastructure for rendering, blocking, navigation, extraction, validation, and data quality. A clever prompt is not enough if the agent fails at the layer below the model -- if it cannot access the page, understand the rendered state, avoid being blocked, preserve evidence, or validate the result, the agent's reasoning may never reach the real problem.
This is where web scraping expertise has something specific to contribute to the AI-agent conversation: not generic commentary about AI, but practical knowledge about what breaks when agents meet the live web, and how to design systems that can recover. The Agentic web scraping: Hype, reality and what happens next post maps out the specific failure modes in detail -- it is a useful grounding document for anyone building agents that touch the open web.
It is also where infrastructure matters. Zyte API is designed to sit at this layer, giving agents reliable access to the messy web instead of leaving every workflow to rebuild unblocking, browser automation, and extraction from scratch. Pair that with Scrapy Cloud for hosting and scheduling, and the infrastructure question becomes much less of a distraction from the design question. The point is not that every agent needs the same stack -- it is that prompt-to-data systems need a web-data operating layer beneath the prompt. One that covers access, crawling logic, schema, validation, observability, failure handling, and human handoff.
In other words: the trust layer.
The bridge between prompt and data
"AI will replace web scraping developers" is the wrong frame. A more accurate one is that AI changes where developer judgment sits. Some implementation work becomes faster. Some QA work becomes more scalable. Some extraction tasks become easier to start. But the need for judgment moves upward into requirements, architecture, validation, failure handling, and control. The 2026 web scraping industry outlook puts it well: you have to touch fewer buttons, but you're still the one driving.
If the last generation of web scraping work was defined by spiders, selectors, proxies, browsers, and pipelines, the next generation adds a layer: agentic system design. The developer still needs to understand the web, still needs to understand crawling, extraction, schemas, data quality, and maintenance. But they also need to design how AI participates in the workflow:
- What the agent can do independently
- What tools it can call
- How context is prepared
- How outputs are tested
- How failures are detected
- How uncertainty is represented
- When humans approve or reject decisions
- How learnings flow back into the system
The work becomes less about typing every line manually and more about creating the conditions under which automation can be trusted.
The future of web scraping is not simply agents that scrape. It is trustable web-data systems -- and those systems need people who understand both sides of the problem: the new agentic workflows and the old messy web. That is the next shape of the web scraping developer: not replaced by the agent, but responsible for designing the bridge between prompt and data.
Questions for builders
We are exploring this shift with developers and teams building AI plus web-data workflows. The most useful public question may be: what would make you trust a web-data agent in production?
That breaks into harder questions:
- Which parts of web data acquisition do you want fully automated, and which should remain under human review?
- How should an agent know it is blocked, incomplete, or wrong?
- What evidence would make you trust the output?
- Who is the real user of the workflow: a scraping engineer, a data team, an analyst, or an end user?
- What would make a web-data agent production-ready?
If you are building agents that need live web access, extraction, validation, or data quality, we would love to hear what you are learning. Join the conversation in the Extract Data community -- the most interesting answers are probably already living in someone's draft, ticket, or postmortem somewhere. That is where this field will get interesting: not in the clean demos, but in the messy systems that survive contact with the web.





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
