Zyte Blog
Field notes from the world of data extraction.
Articles, interviews and analysis on how data is gathered, used and fought over — written by the people closest to it.
Browse
Hot topics
Latest
What we've been publishing
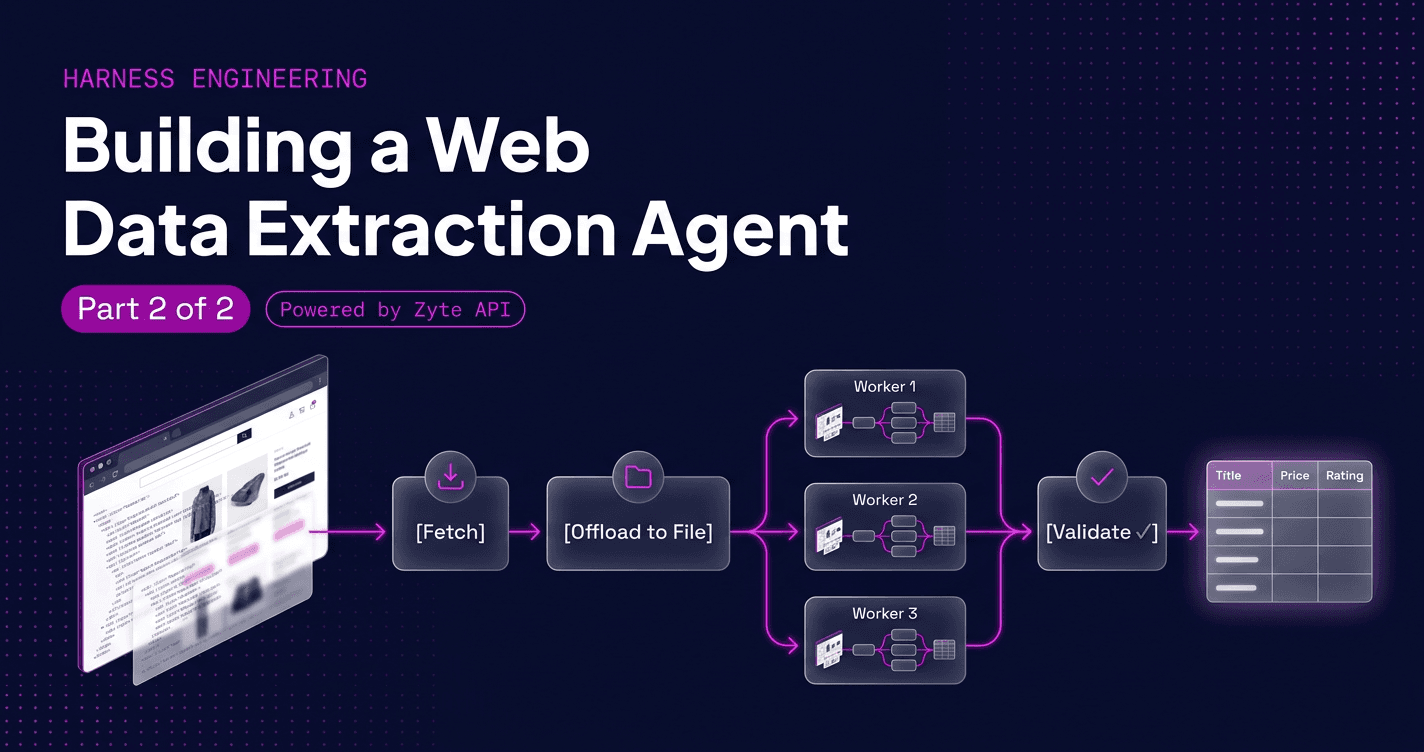
Harness Engineering, part 2: harnessing a data extraction agent
Point it at a website, tell it which fields you want, get back clean structured records. That's the agent we're designing in this post — and the interesting part isn't the model, it's the harness decisions that make it actually reliable at scale.

Harness Engineering, part 1: what is an agent harness and why it matters
Same model, same weights, zero retraining — LangChain changed nothing but the scaffolding around a coding model and jumped it from 30th place to the top five on a benchmark. That scaffolding has a name: the harness. And it's the part you actually control.
The harness matters more than the model - Podcast EP07
"The model is the engine — but the harness is everything else." In Episode 7, we dig into why the infrastructure layer around your AI model matters more than the model itself, rank the best models available right now, and ask whether the open-weighted revolution is about to make frontier subscriptions obsolete.

Zyte's first Developer Community Meetup: the recap, slides, and recording
AI agents can now write, run, and self-heal your web scrapers, and in Zyte's first-ever Web Scraping Community Meetup we show you exactly how. Live demos, a Claude Code plugin that turns a prompt into production-ready data, and a fireside chat on where AI is really heading.

How to run any model inside Claude Code
I run GLM 5.2 inside Claude Code with the same tools, the same skills, and the same agent loop. Three environment variables is all it takes.

The best agent skill is the one that says the least
More instruction, worse output. Zyte's head of R&D on why telling your agent exactly what to do can blind it to the obvious answer.

Why I'm adding GLM-5.2 to my agentic coding arsenal
Is GLM-5.2 really closing the gap to Anthropic - and at just a fraction of the cost - or is it just more AI hype? I think so, and let me show you why.

How to build your first Scrapy extension
My Scrapy project now plays a triumphant fanfare when a crawl finishes clean and a sad trombone when it doesn't, which is also how I finally learned what Scrapy's extension points are actually for.

My personal agent setup: the architecture that runs my household and my DevRel work
"Four people, four diets, two work schedules, and a baby who answers to nobody. That's what finally made me build a personal agent." A walkthrough of the actual architecture I run to hold my household and my DevRel work together — profiles, skills, memory, and the web-data layer that makes it all reach the live web.

Data is the new water
For 20 years, we were told “data is the new oil”. That’s no longer true. In the era of the fluid web, information is more fundamental, cleaner and abundant than that.

Building robust agentic AI workflows with rapid web data
AI agents need access to public web data, right now. Tools connected to web scraping APIs empower agents to return live data quickly.
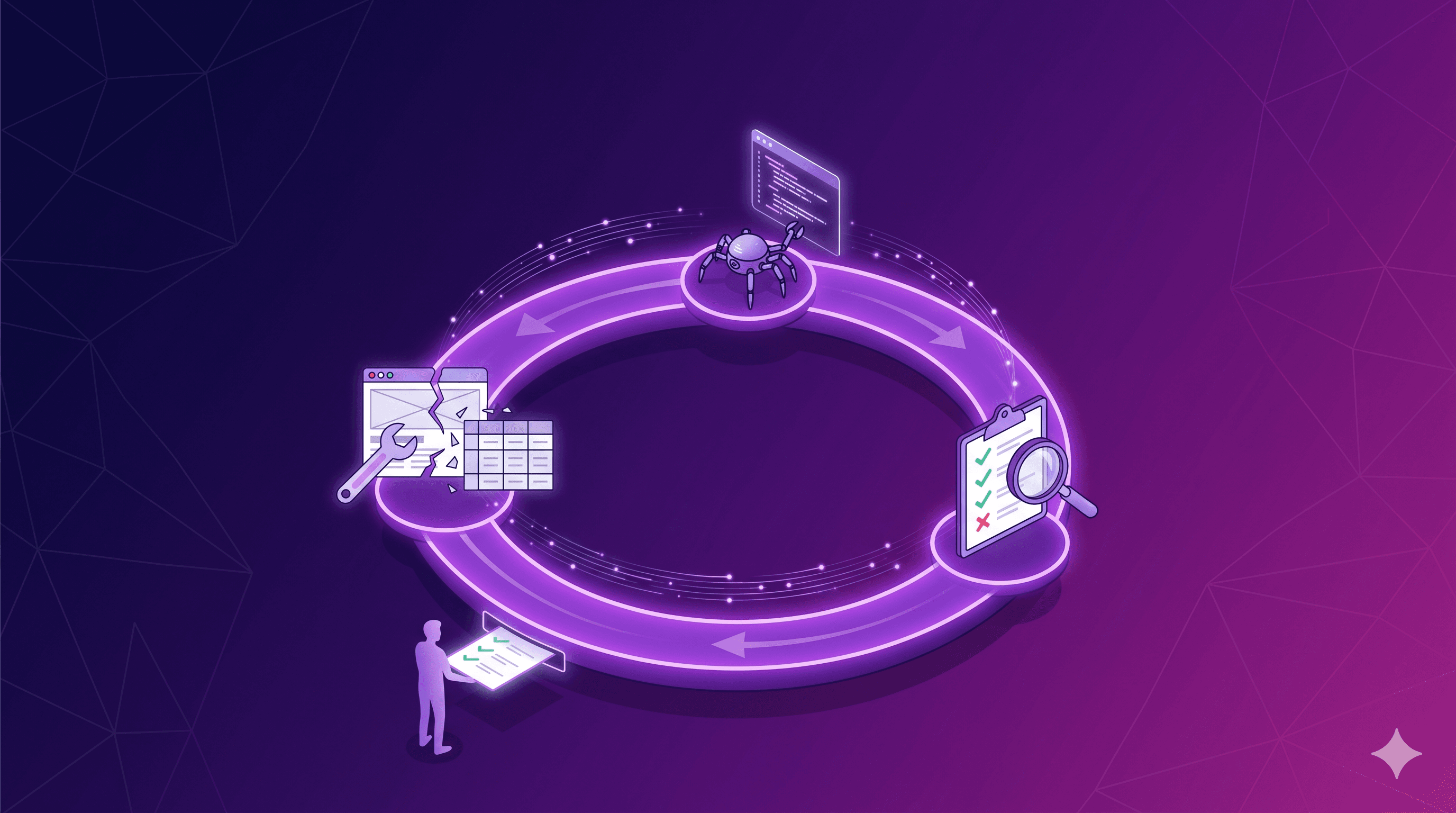
Now what exactly is loop engineering? And where do Anthropic's Fable 5 model and web scraping fit in?
A viral clip from Claude Code's creator put a name to something a lot of us have been circling: loop engineering. Here's why web scraping may be its best-fit domain — and what that means in practice.
Zyte YouTube
Watch & learn

Video · Zyte YouTube
Screenshot webpages with this Claude Skill and Zyte API
March 6, 2026

Video · Zyte YouTube
0% Hallucination? RAG + Web Scraping (Step-by-Step)
March 5, 2026

Video · Zyte YouTube
Generate HTML Parsing code the right way with Scrapy & Web Scraping Copilot
February 23, 2026

Video · Zyte YouTube
Zyte API Sessions - flexible cookie management maintaining control
February 6, 2026

Video · Zyte YouTube
How to transfer browser cookies to an http session when web scraping
January 27, 2026
Events & community
Where Zyte shows up
 7–8 Oct 2026
7–8 Oct 2026Extract Summit 2026 — Austin, TX
In-person conference · Austin, TX
 10–11 Nov 2026
10–11 Nov 2026Extract Summit 2026 — Dublin
In-person conference · Dublin, Ireland
2026 Web Scraping Industry Report by Zyte
Webinar · On demand
Extract Summit 2025 — Dublin
In-person conference · Dublin, Ireland




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
