Field notes from the world of data extraction.
Articles, interviews and analysis on how data is gathered, used and fought over — written by the people closest to it.
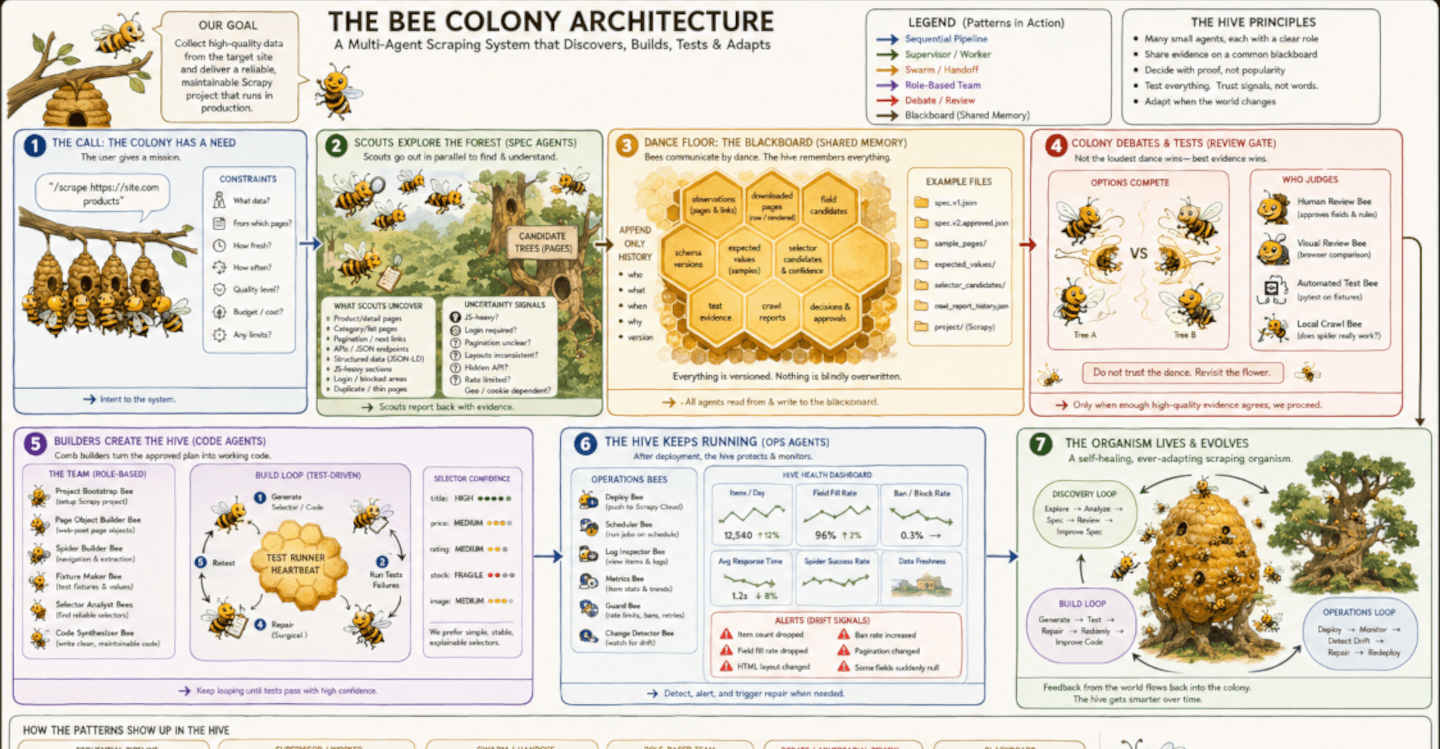
What multi-agent orchestration looks like in a large-scale web scraping project
Multi-agent orchestration is having its moment. The diagrams are everywhere now. Boxes for planners, boxes for hands, boxes for daemons, arrows to a shared brain, a human floating at the top. They keep getting prettier. The part where the web pushes back is still the part nobody draws.

Announcing powerful new spending controls and usage insights for Zyte API
Consign bill-shock to the trashcan. New custom spending limits and usage insights put data-gatherers in control.

Meet the new-look Zyte Domain Health Hub: Your command center for data extraction performance
Monitor your data-gathering pipelines like a boss - and act on domain issues in real-time.

NotAnInterview: “I Have Superpowers Now"
The problem was a project with 12,000 websites to crawl, and there’s no world where you write custom spiders for 12,000 websites, not with a human team and certainly not sustainably. So Javier built a workflow: a set of AI prompts that could analyze a website, figure out its structure, and generate a crawl configuration that a generic spider could then use.

Building a self-hosted browser scraping service (is it more hassle than its worth?)
If you want to understand exactly how a browser scraping service works at the infrastructure level, or you have a steady workload that you want running on hardware you already own, building one yourself teaches you things that matter. Here's how I did it

Web scraping on 22 KB of RAM: Fitting the world on an ESP8266 microcontroller
Data-gathering doesn’t have to be memory-intensive. You can fit the world’s weather on a 9cm-square board, when you move the work to a web scraping API.
I built scraping agents for 30 days - here’s what I learned
For the last 30 days, I did one thing almost exclusively: I built scraping systems with AI agents, from the ground up, across real targets, with real deadlines. Not prototypes designed to impress in a demo, not isolated experiments running against a toy website, but production-grade pipelines that needed to ship and keep running.

I'm not the same developer I was before LLMs
I've been running a series of conversations with developers at Zyte to understand what's actually changed in the way they work since LLMs showed up. Not the headlines. The day-to-day. What they delegate, what they don't, what they notice, what surprises them. This one was different on two counts.
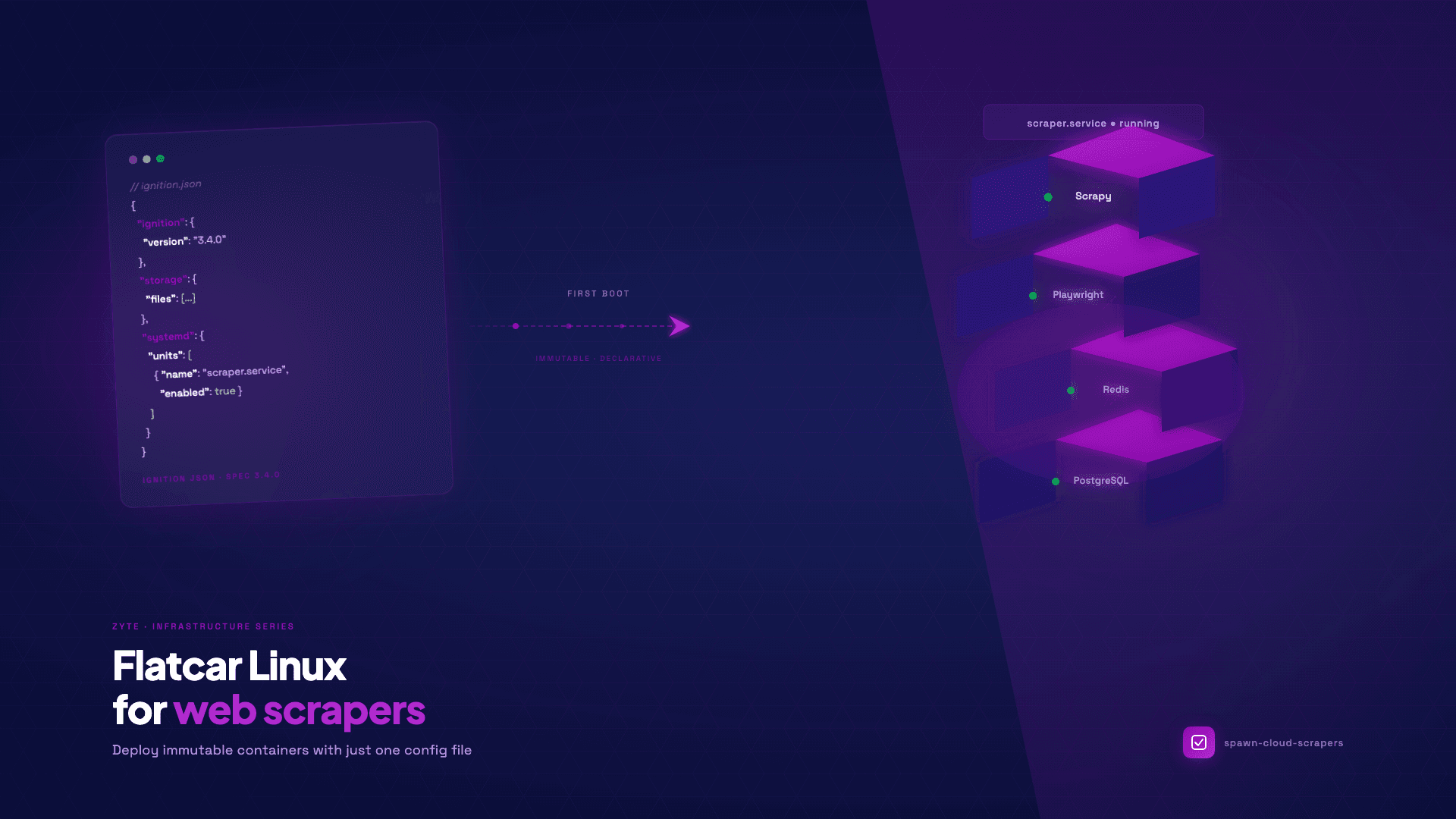
Flatcar Linux for web scrapers: deploy immutable containers with just one config file
The next time you spin up a VPS to give it a persistent home, you spend the better part of an afternoon rebuilding from memory. Here's a tool to help using Flatcar Linux
My agentic coding setup: Claude Code, multi-agent orchestration, and how I actually work
Ayan's 4 agent team, using Claude's /goal, and the models and coding agents he uses to code effectively.

llms.txt isn’t dead: How we put dev docs in AI’s spotlight
Marketers are giving up on the idea of plain-text pages - but llms.txt and Markdown are how we’ll get our docs in the hands of LLMs and developers.

The great wall of data: The complexities of web scraping in the Asian market
While the technological arms race of web data access is universal, the battleground in Asia has its own unique rules of engagement.




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
